引言
Stable Difussion的作用主要是生图,而图片之所以能产生价值,一定是符合应用落地的某些需求,这就要求咱们从”随机生成”逐步迈向”精准控制”。
目前在comfyUI中,大致有这么几个主要方式可以进行控图。
- 模型本身,提示词,LoRA,TIIPAdapter
- IPAdapter
- ControlNet & InstantID
本文主要就ControlNet和InstantID进行总结
一、ControlNet
1.1 初步认识ControlNet
| |
|---|
| 如果IP-Adapter是将图片中的风格、身份特征的视觉信息进行迁移,那么ControNet就是能从参考图中,用各种专业的分析工具(预处理器)提取更多不同维度、不同层级的视觉信息,然后增强设计需求说明文档(promt embedding),从而并引导雕塑家(Unet model)雕塑创作。 |
| - Prompt Embedding(NEG+POS):CLIP FOR TEXT PROMPT的输出
- Control Image:引导控制图,用于约束引导雕塑过程。
- ControlNet Model:将引导控制图转换成赛博雕塑世界能识别的引导手册,并给到雕塑家在雕塑过程中用于参考。
- Prompt Embedding:被增强过的设计需求说明文档(CLIP FOR TEXT PROMPT的输出),用于引导雕塑家(Unet Model)进行雕刻。
|
| ControlNet 并没有直接理解像素图像,它首先需要一个一些分析工具。这个分析工具会分析你的原始图像,并根据你选择的 ControlNet 类型,从中提取出非常具体的、结构化的“条件图像”。条件图像大致分为以下类型 - Canny(边缘):提取图像中最清晰、最锐利的边缘线。它对图像的明暗交界、颜色突变非常敏感。适用场景:需要严格保持物体形状、建筑结构、人物轮廓的精确性。
- Lineart(线条艺术):提取更具艺术感、更像手绘线稿的线条,它通常能处理主线和细节线。适用场景:将照片转绘成漫画、插画、日系动漫线条风格。
- Softedge / HED / PIDS (柔和边缘):提取更柔和、更艺术化、更不那么锐利的边缘信息,有时也能捕捉到物体间的微妙边界和阴影过渡。适用场景:希望保持大致构图,但又想给 AI 更多自由度去填充细节和风格时;避免线条过硬而影响融合。
- OpenPose (人体骨架):精确检测人物的骨骼关键点、身体姿态、肢体朝向,以及手部和面部(眼睛、鼻子、嘴巴等)的关键点。适用场景: 精准控制人物的动作、站姿、手势、身体朝向等,而完全不限制人物的外貌、服装和风格。
- Depth (深度图):检测图像中物体到相机的距离信息。近的物体显示为白色/亮色,远的物体显示为黑色/暗色,形成一张灰度图。适用场景:保持原图的透视关系、场景景深、物体间的远近布局。(PS:我感觉用来控制人物姿态很合适)
- Normal Map (法线图):检测图像中物体表面的朝向信息。它用 RGB 颜色编码了物体表面在三维空间中法线(垂直于表面的方向)的 X、Y、Z 分量。适用场景: 精确引导图像的光照效果、阴影分布、物体表面的立体感和材质细节。
- MLSD (直线检测):专门检测图像中所有直线结构,例如建筑、房间、家具的边缘。适用场景: 保持建筑效果图、室内设计图、几何结构图像的规整性和精确性。
- Segmentation (语义分割):将图像中的不同物体或区域进行语义上的划分(例如识别出“人”、“车”、“树”、“天空”、“道路”等),并用不同的颜色或标签进行标注。适用场景: 根据区域填充内容,例如将“蓝色区域”替换为天空,“红色区域”替换为建筑。
- Shuffle (像素混洗):将参考图像的像素特征打乱重排,然后作为条件注入。它不提取具体的结构,而是将原图的整体视觉特征(如色彩、质感、部分抽象内容)以混洗的方式传递。适用场景: 粗略地借鉴参考图的整体构图、色彩和风格,同时给予 AI 很大的自由度进行内容重构。
|
| 接收条件图像,并将其转换成赛博雕塑世界能理解的参考图,并以该参考图约束引导雕塑家的雕刻过程。 通常来说,不同的条件图像,需要用不同的CN模型来处理。 |
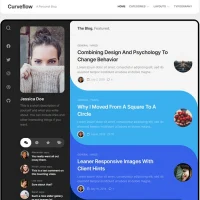
1.2 CN基本工作流(depth)图示
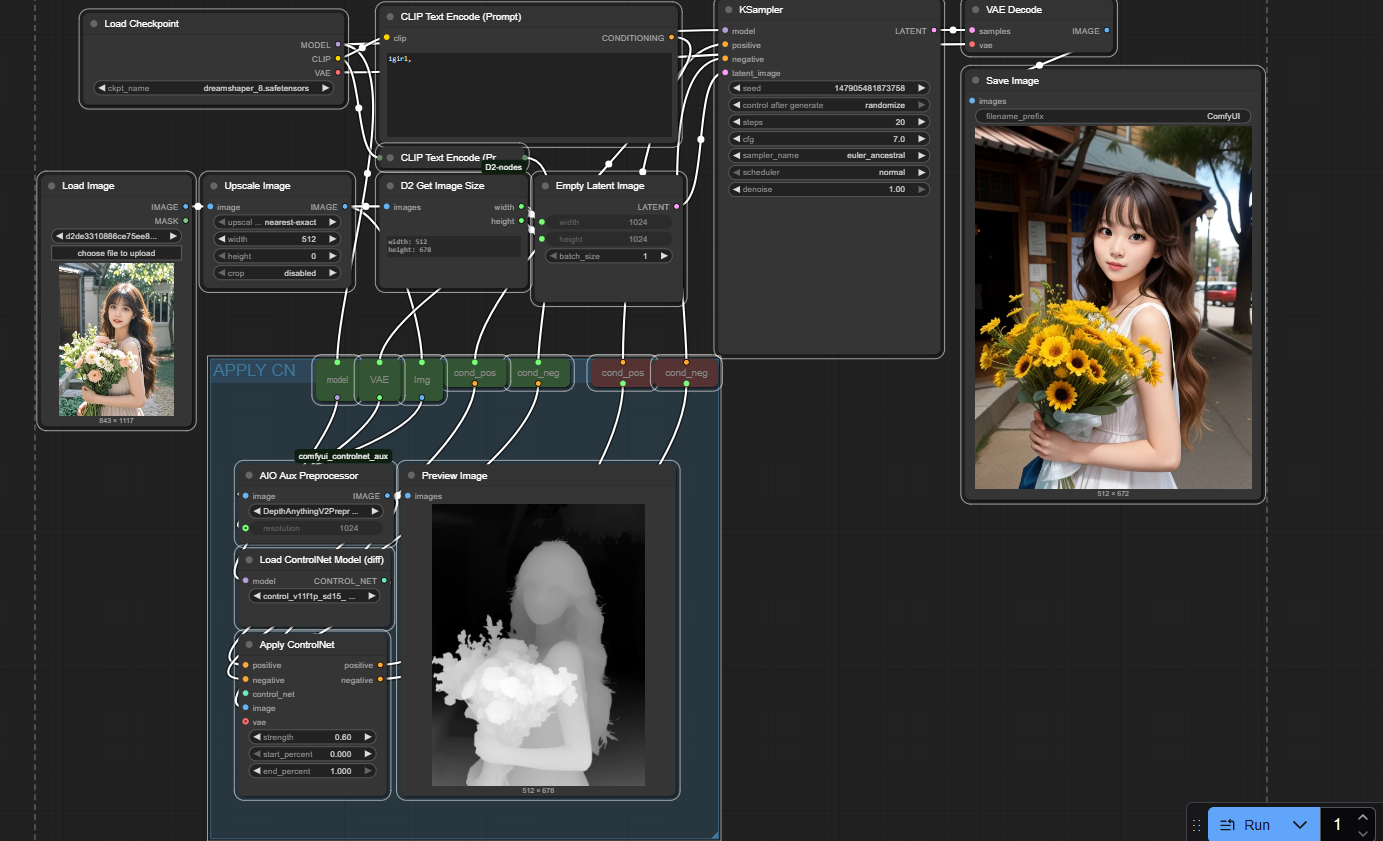
1.3 基本节点介绍&参数理解
| |
|---|
| CN的核心节点,整体作用是对prompt embeddng(pos+neg)进行增强,可以理解为将控制信息添加到prompt embedding(pos+neg)中,就好比在设计需求说明文档中添加各种维度的约束信息 - positive:即positive prompt embedding(condition+,condition positive)
- negative:即negative prompt embedding(condition-,condition negative),两者好比就是把设计需求说明书传入,进行增强补充。
- image:即contronet image,如果要使用参考图(常规人眼看的图)中的控制信息(如结构,风格,光影,姿势),通常需要一个转换工具preprocessor进行提前转换。如图中depth控制图。
- Control_net:即Controlnet model,其作用就是将控制图中的信息解析并转到到prompt embedding中,好比就是从controlnet img提取出来的控制信息补充添加到设计需求说明书中。
- vae:说是能提供对控制信息的编码和解码,从而提高控制信息的质量和准确性,暂无明显体感。
- model:有些节点会要求传入unetmodel,仅用于判断CN model 和 model是否匹配。一般来说unet model 与 CN model 要求匹配。SD15匹配SD15,SDXL 匹配SDXL。
- strength:对控制信息的遵循程度,默认为1.
- start_percent:决定该控制信息什么时间点生效。
- end_percent:决定该控制信息什么时间点结束。
- positive&negative:即 prompt embedding(condition+,condition positive),也可以看做是被增强补充控制信息的设计需求说明书。
|
| - image:即正常的像素图片,需要将其转换成control img。
- Preprcessor model:选择preprocessor的类型,不同类型的model会生成不同的control img
- resolusion:分辨率,默认512。个人喜欢直接设置为latent width。
- image:即control image,作为Apply Controlnet节点的核心输入之一。
|
| - 不同类型的控制图需要对应的CN model
- 不同类型的unet mdoel 需要对应的 CN model,如SD15的unet model则需要SD15的CN model,SDXL等类推
|
二、InstantID
2.1 初步了解InstantID
在视觉信息中,各种维度(结构,线条,笔触,颜色,光影等)都可以通过Controlnet进行控制,只要达到大致相当我们便能接受,但当咱们需要高度保持原图中的信息时,通常达不到我们的期望,如风景还原度,人物还原度,又或是其他。
而InstantID则通过还原脸部信息,从而提高人物还原度。
重要:截止更新时间为止,InstantID适用于SDXL版本
2.2 工作流图示
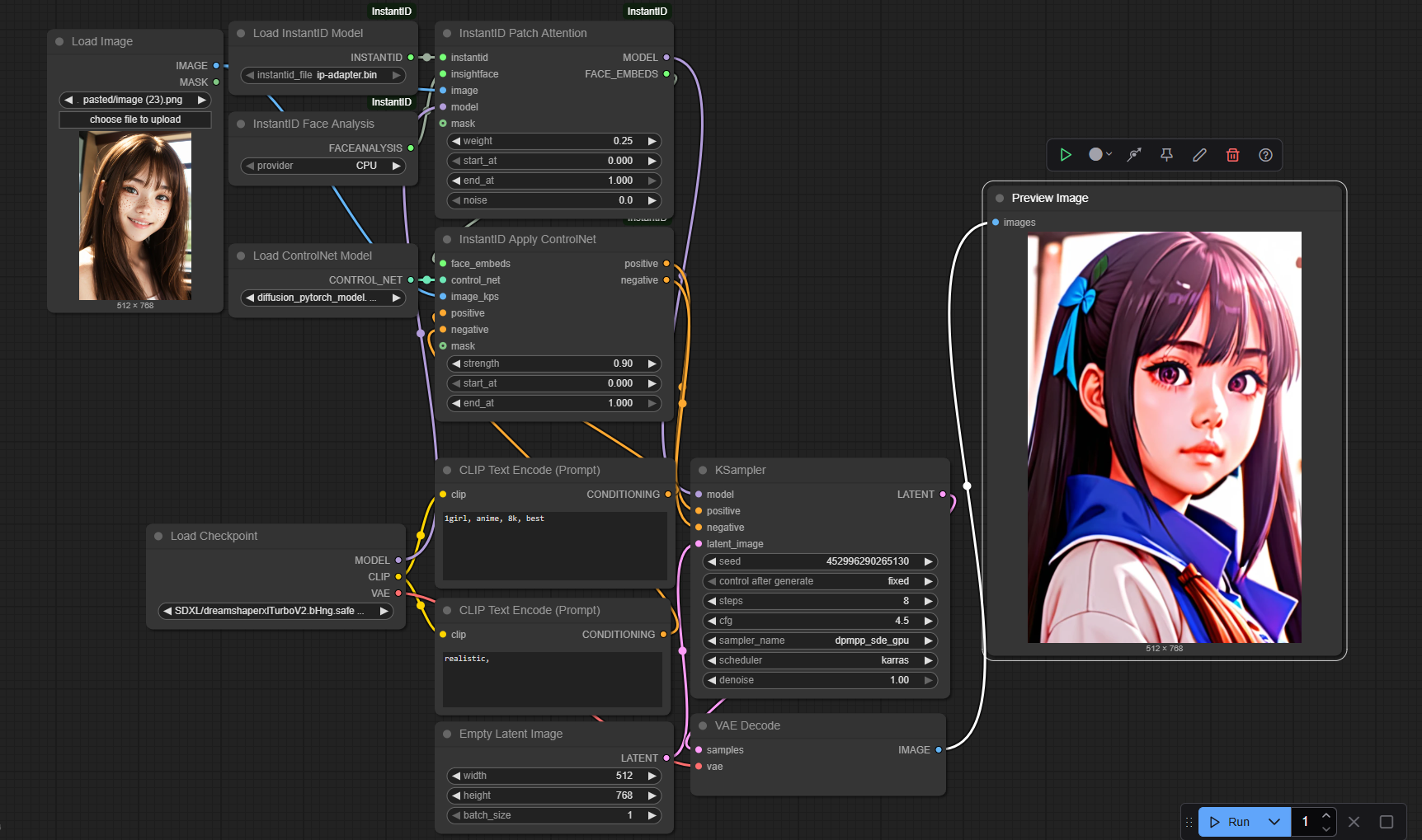
2.3基本节点介绍&参数理解
| |
|---|
InstantID Patch Attention | 用于提取脸部信息,并与UNET Model进行适配,好比提取了脸部特征信息后,让雕塑家进行学习,从而获得画这张脸的能力。
核心输入 - image:脸部参考图,建议只用脸部区域的图。
- insightface:识别人脸信息,提取face embeds
- model:即unet model
- instantid:即传入instantid model,该model的作用是将提取后的人脸信息注入到unet model中,好比让雕塑家学习这个人脸过程,具备画该脸的能力。注意:只是多了个能力,而不是只有画该脸的能力
- ip_weight:可以理解为unet model的学习力度。
- start/end_at:开始调用该能力的时间段。
- noise:官方指明不加noise可能会有毁图,可能类图生图重绘,加上点泥巴后,才能更好的应用该能力,更丝滑一点。建议0.35以下,作者一般用0.2。
- model:适配过脸部信息的unetmodel,好比已经学习过该脸部信息的雕塑家。
- face embeds:脸部特征信息
|
| 加载instantID model,官方指定了一个模型,名为ip_adpter.bin,至于为什么名为ip_adpter,说是基于IPAdapter。
作为InstantID Patch Attention节点的核心输入之一。 |
| 提取脸部特征的模型,专用于识别并提取脸部信息,需按照github中的指引进行下载并放置在指定路径。
作为作为InstantID Patch Attention节点的核心输入之一。 |
InstantID Apply ControlNet | 将face embeds(脸部信息)和脸部姿态(通过image_kps预处理后获得)增强补充到prompt embedding(设计需求说明书)中,告诉unet model我们要雕刻谁。实验过程中,我有这么一种理解,instantID是让雕塑家学习这张脸,但是雕塑家只是多了这么一张脸的信息,而真正雕刻时,雕刻什么样的脸是由设计需求说明书来确定。
核心输入 - face embeds:脸部信息
- prompt embedding(pos+neg):即设计需求说明书。
- image_kps:脸部姿态关键点(眼鼻嘴)参考图像。
- Controlnet:cn model,她能在设计需求说明书中奖脸部特征和脸部姿态等信息增强补充。
- prompt embedding(pos+neg):被补充增强的设计需求说明书,告诉unet model要画哪张脸,脸部姿态是怎么样的。
|
| |