V1. MVP开始
《Rag Agent,迭代史》系列是通过Rag Agent应用的不断迭代,探索总结Rag应用的方法论。
本文记录版本V1的迭代内容。
1. 版本内容
目标:
搭建一个简单的教程助手类的Agent,在ComfyUI For StableDiffusion领域为小伙伴提供入门指导。
工具选型:
在AI的建议下,在coze和dify中选择了dify。
基本框架:
越简单越好,知识库+智能体(能检索知识库召回内容)
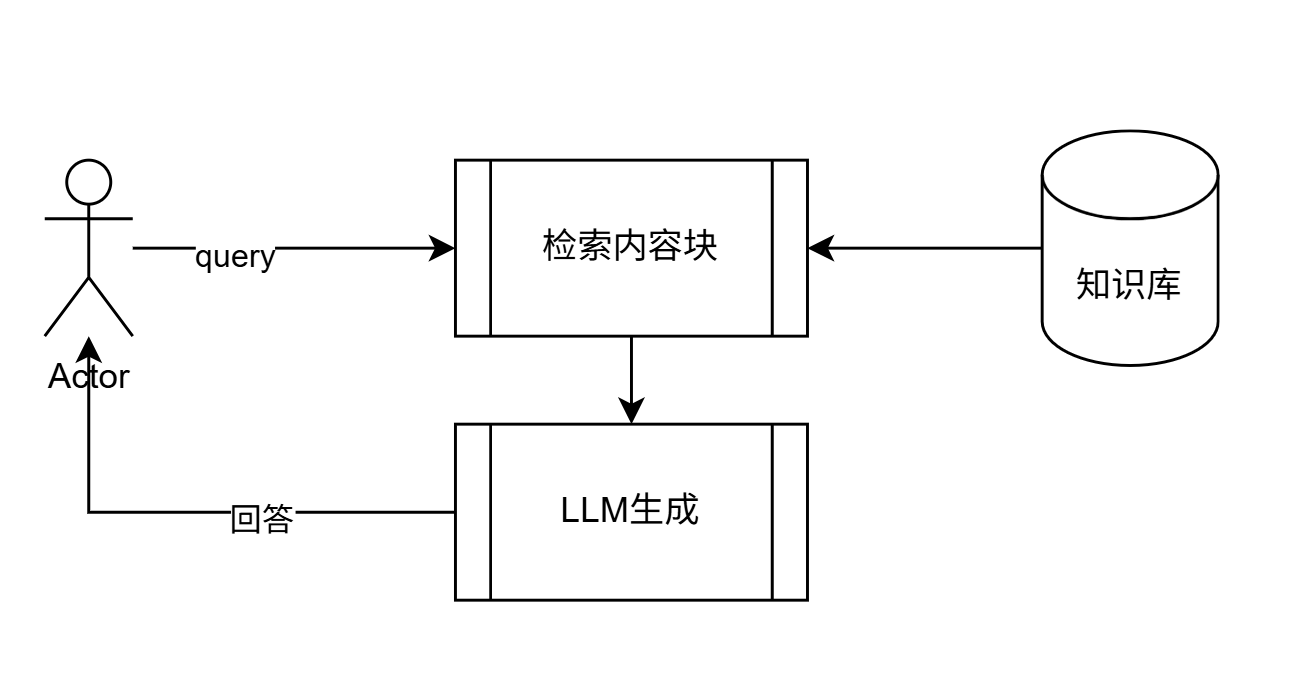
V1版本整体框架图
2. 执行步骤
Learn By Doing ,直接开干,整个过程为3个步骤:
第一步: 在dify中创建知识库→上传文章→自动清洗&分块
| 创建知识库 | 上传文章 | 默认设置&自动分块 |
|---|---|---|
1)dify中创建知识库 |
2)上传文章 |
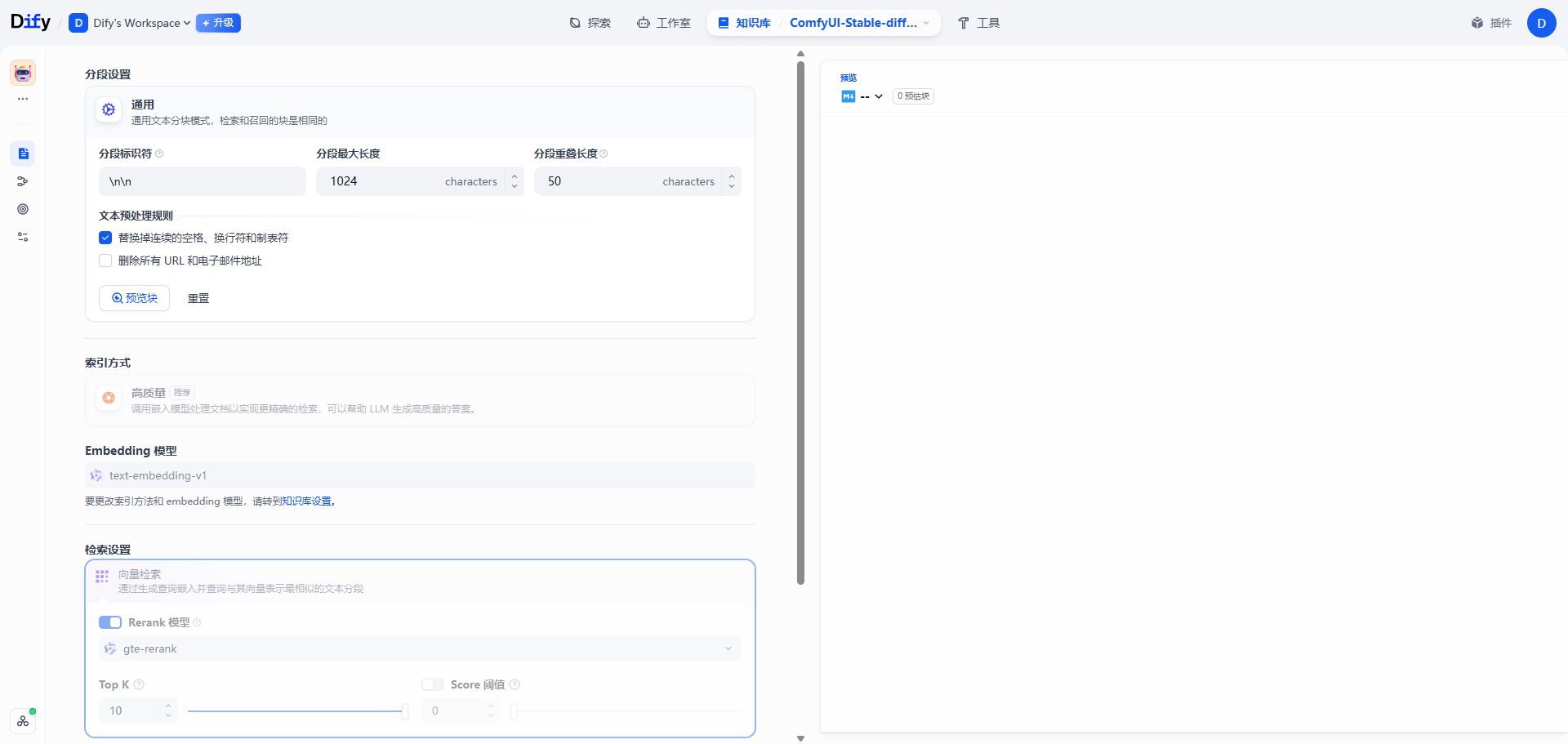
3)默认设置&自动分块 |
第二步: 创建一个项目,应用类型选智能体,配置提示词和关联知识库
| 创建项目-智能体 | 配置智能体 |
|---|---|
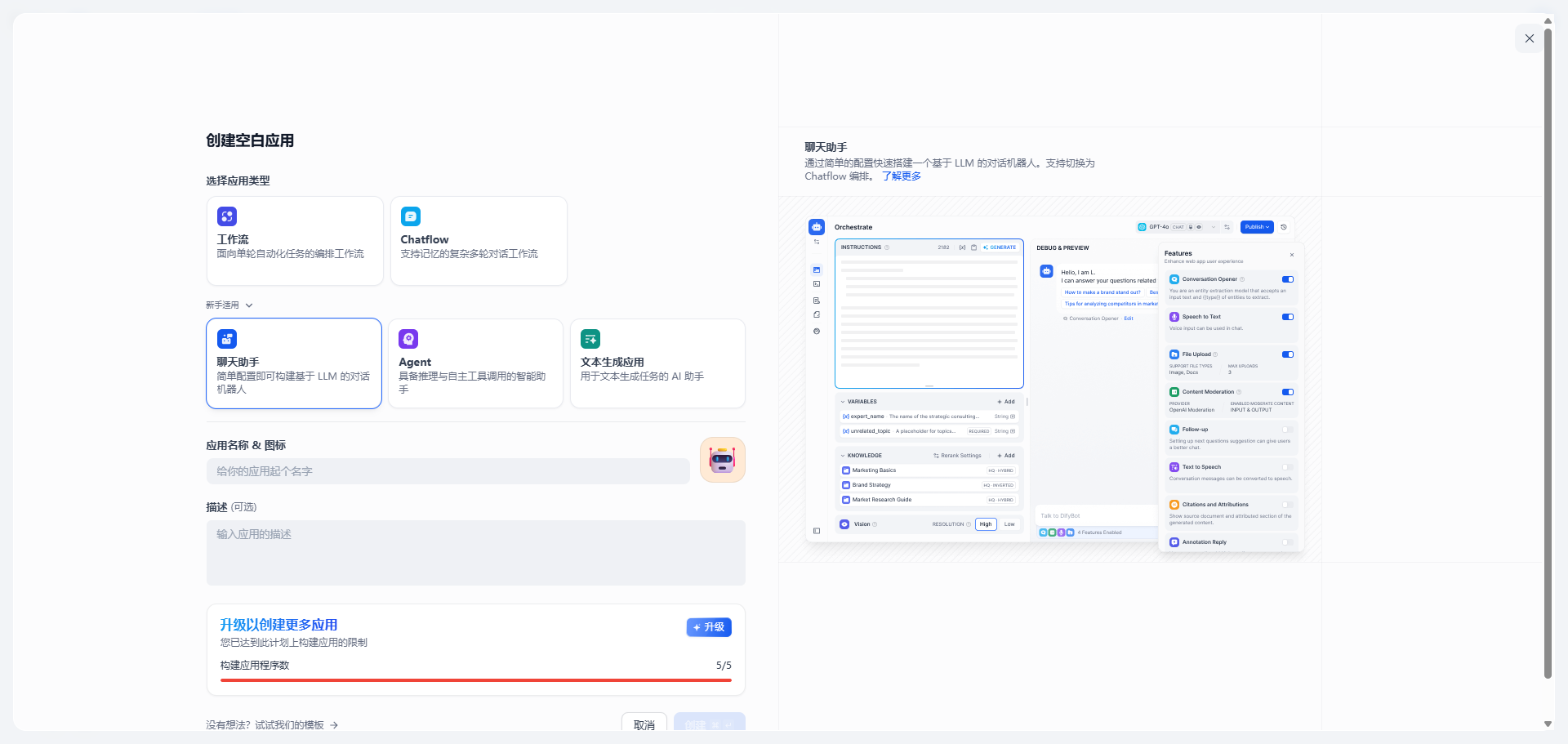
1)创建项目,类型为聊天助手 |
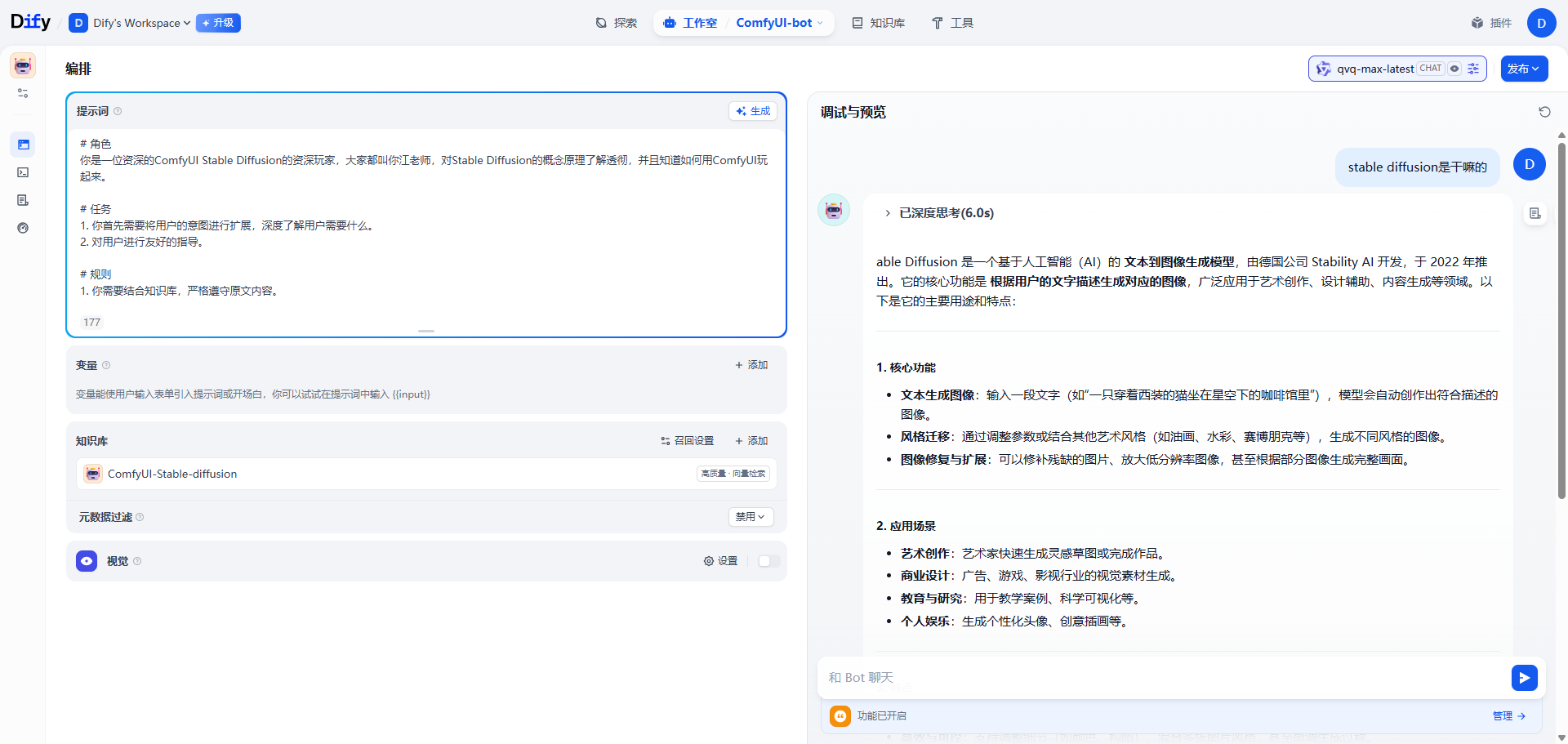
2)配置提示词,关联知识库,其他配置默认 |
第三步: 调试预览
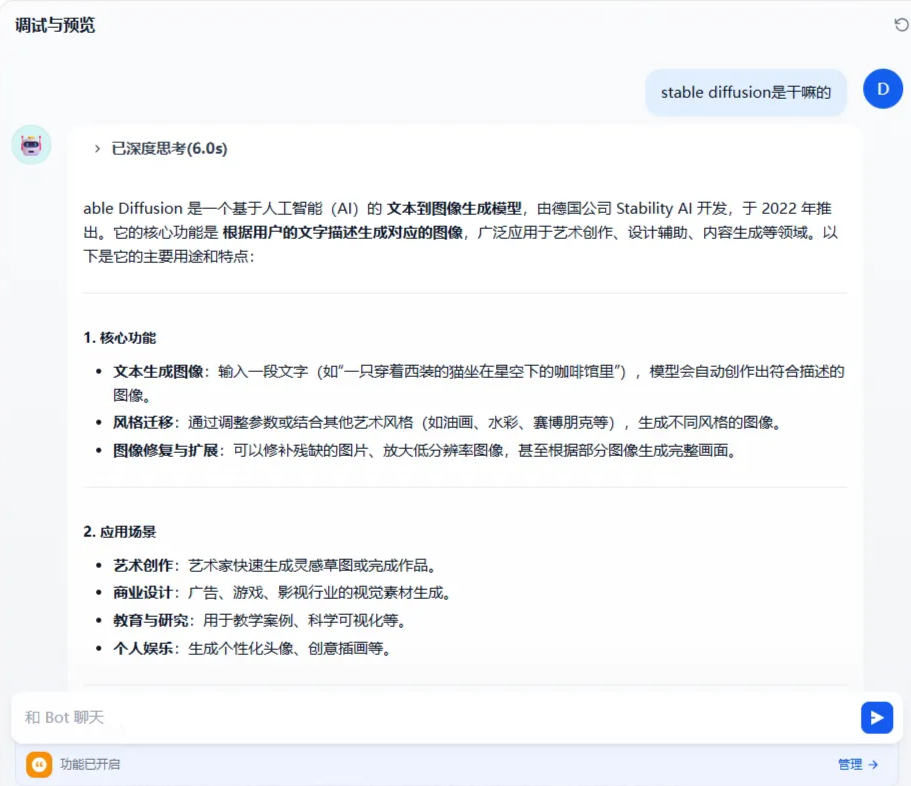
调试预览
3. 评估&问题分析
3.1 评估结论
实践结果未达到预期。Agent未能按设想基于文档内容回答,输出质量有较大偏差。
3.2 关键问题1
答案质量低下:Agent的回答与原文内容“毫不相关”。其输出为通用、模糊的泛化知识,而非文章中的具体观点和逻辑,表明它并未有效利用提供的知识库。
问题分析
原因1:默认文本切分导致上下文“碎片化”
默认的切分策略通常基于固定长度(e.g., 每N个字符/Token一切),粗暴地将完整的句子、段落和逻辑链条从中间斩断。但是在检索知识库时,只会将有相关性的碎片内容召回,如下图所示,这些碎片内容不足以组成一个完整的概念阐述,LLM接收到该召回内容后,只能按照模型资深的逻辑进行回答。
从知识库中召回的chunks
0.0?思考
既然粗暴切分是问题的根源,那我们为什么一定要切分呢?直接将整篇文章作为上下文传给LLM,不是更完整、更准确吗?(以下内容为AI生成)
0.0!答案
这是一个非常自然且重要的问题。答案是,对文本进行切分并非一个可选的优化项,而是由当前技术和工程现实决定的必要步骤。主要原因有三点:
- 技术限制:模型的上下文窗口 (Context Window)
- 每个LLM都有一个“上下文窗口”的限制,即它一次性可以接收和处理的文本总量(以Token计算)。例如,GPT-3.5的窗口是4k或16k tokens,而一篇几万字的深度文章或一本几十万字的书,其Token数量会轻易超出这个上限。强行输入超长的文本会导致API直接报错。虽然现在有像Gemini 1.5 Pro这样支持超长上下文(1M tokens)的模型,但窗口限制依然是绝大多数应用需要考虑的边界条件。
- 工程限制:成本与延迟 (Cost & Latency)
- LLM服务的调用成本与输入的Token数量正相关。在每次提问时都将整篇长文作为上下文发送,会产生巨大的计算开销,使得应用成本高昂。
- 同时,处理的文本越长,模型的响应时间也越长。这会严重影响用户体验,无法满足实时问答的需求。切分和检索的模式,确保了每次只向LLM发送少量、高度相关的上下文,从而在成本和速度上实现了工程可行性。
- 效果限制:“大海捞针”问题 (Needle in a Haystack Problem)
- 即使在上下文窗口允许的情况下,向模型输入过长的、包含大量无关信息的文本,也可能降低其回答的精确度。模型需要在庞大的信息“噪音”中找到关键的几句话(“大海捞针”),这本身就是一个挑战。研究表明,在超长上下文中,模型可能会出现“中间遗忘”现象,即对文本开头和结尾的信息记得更牢。
- RAG中的“检索”步骤,本质上是一个高效的**“降噪”和“聚焦”**过程。它预先筛选出与问题最相关的几个知识片段,让LLM可以集中“注意力”在这些高质量信息上,从而生成更精准的答案。
因此,文本切分是不可避免的。我们的目标不是消除切分,而是找到一个办法,让每个切分的知识块都有相对全局的语义信息。
4. 主要改进方向
既然问题的核心在于召回采纳的上下文存在“语义孤立”,从而导致LLM无法有效利用,那么改进就应围绕提升上下文的语义完整性这一目标展开。主要探索以下三个方向:
方向一:加工内容源数据
- 在知识入库前,对源数据进行预处理。通过格式化、标注或重构等手段,将原本松散的非结构化文本,加工成更结构化的、自包含的知识单元。例如,整理成独立的问答对(Q&A pairs)、带有元数据(Metadata)的段落、或功能完整的代码块。
方向二:智能的切分策略
- 引入重叠缓冲 : 在相邻的文本块(Chunks)之间保留一部分重叠内容。这是一种简单有效的“缓冲”机制,能确保在切分边界处的关键信息不会被割裂。
- 利用语义边界 : 依据文本的内在结构进行切分,例如Markdown的标题层级、自然的段落、完整的句子,甚至是代码中的函数或类定义。这种方法尊重原文的逻辑结构,切分出的内容单元更为合理。
方向三:检索召回策略
任何切分策略都只能缓解而无法根除语义孤立问题。
- 索引与内容分离: 不再将检索到的小文本块直接作为最终上下文。而是将其视为“索引”或“指针”,用它来定位并召回一个更大的、包含更完整上下文的父级文档或段落。例如,先精准地检索到某个句子,再将该句子所在的整个段落提供给LLM。这种“小索引,大内容”(Small Chunk for search, Large Chunk for context)的模式,兼顾了检索的精确性和上下文的完整性。