1. V2版本内容:
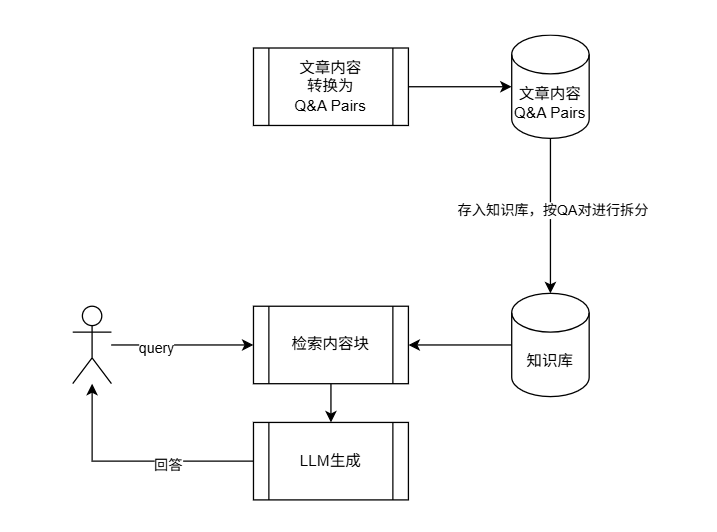
在《Rag Agent,迭代史(一)》_V1MVP版本的实践后,先采用改进方向一,即 加工内容源数据。
在知识入库前,对源数据进行预处理。通过格式化、标注或重构等手段,将原本松散的非结构化文本,加工成更结构化的、自包含的知识单元。
具体措施即将文章整理成独立的问答对(Q&A pairs)、带有元数据(Metadata)的段落、或功能完整的代码块。试着将文章变为问答对,让每个问答对相对来说语义完整。
重大调整:
由于云端dify没有自带的数据库,为了快速验证MVP,从V2版本开始切换到了COZE平台。
2. 执行步骤
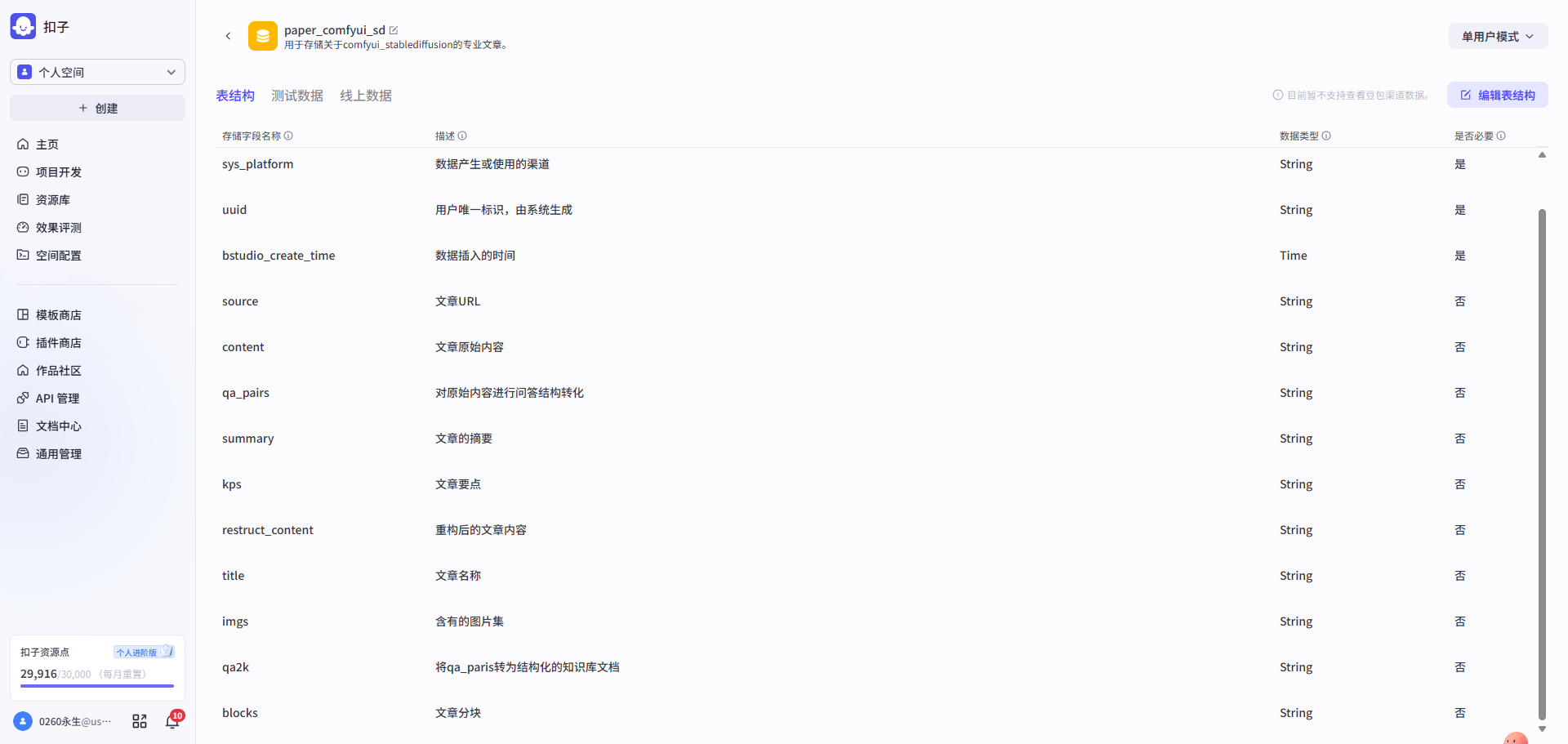
**第一步:**新建数据库&设计表结构→存入文章内容
| 新建数据库 & 设计表结构 | 存入文章内容 |
|---|---|
 |
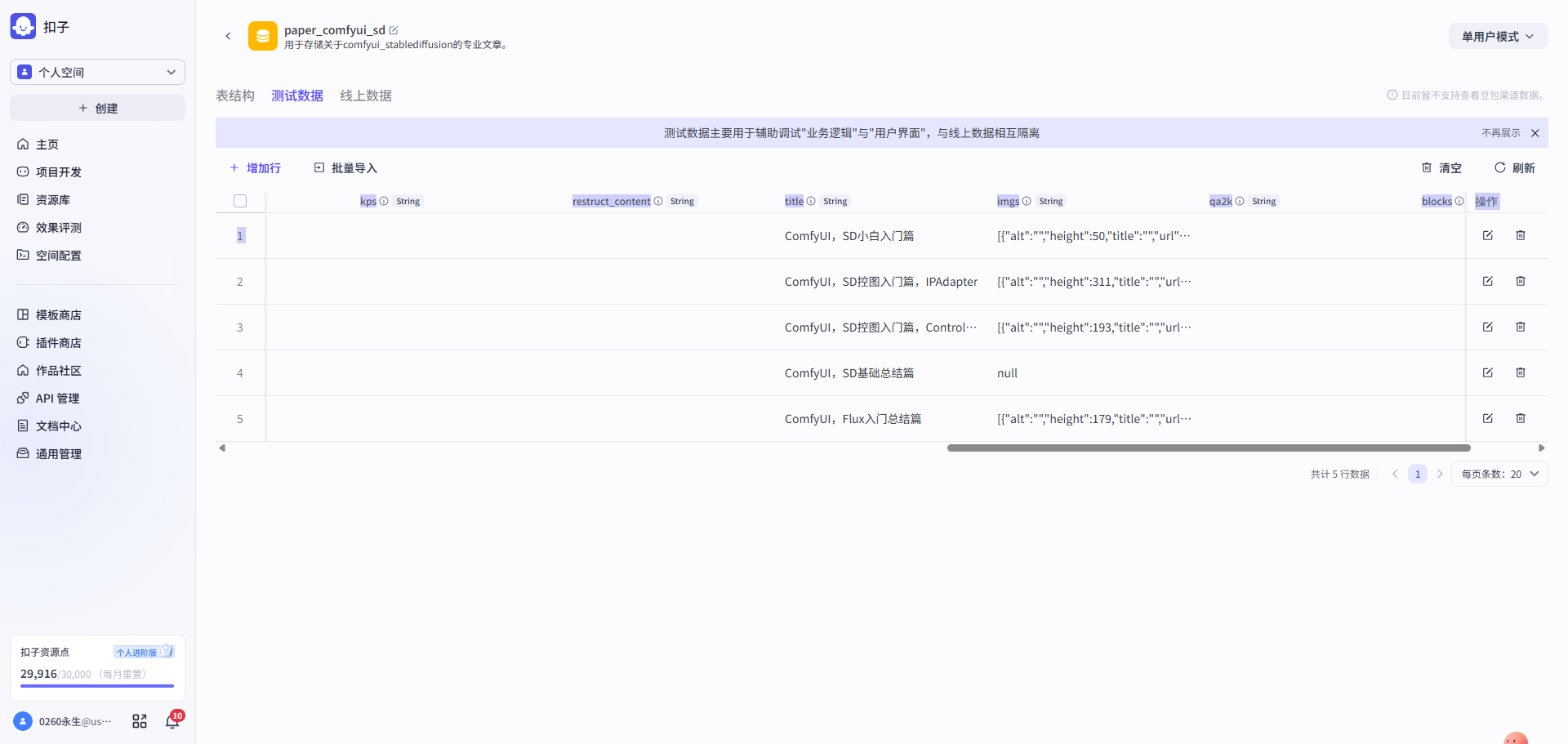 |
| 表结构::id,title,content,url,qa_pairs | 先将文章原始内容导入,其他字段暂时为空 |
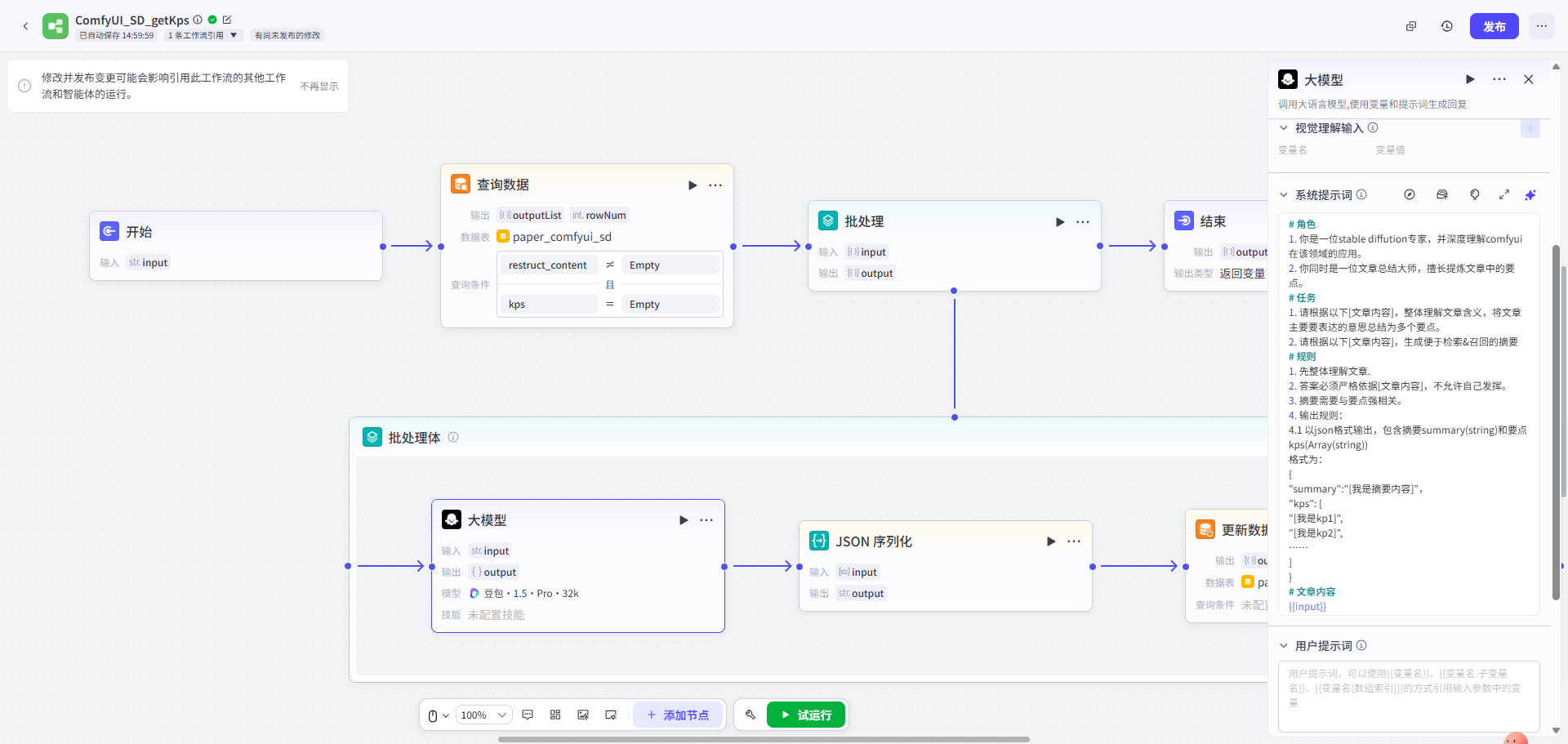
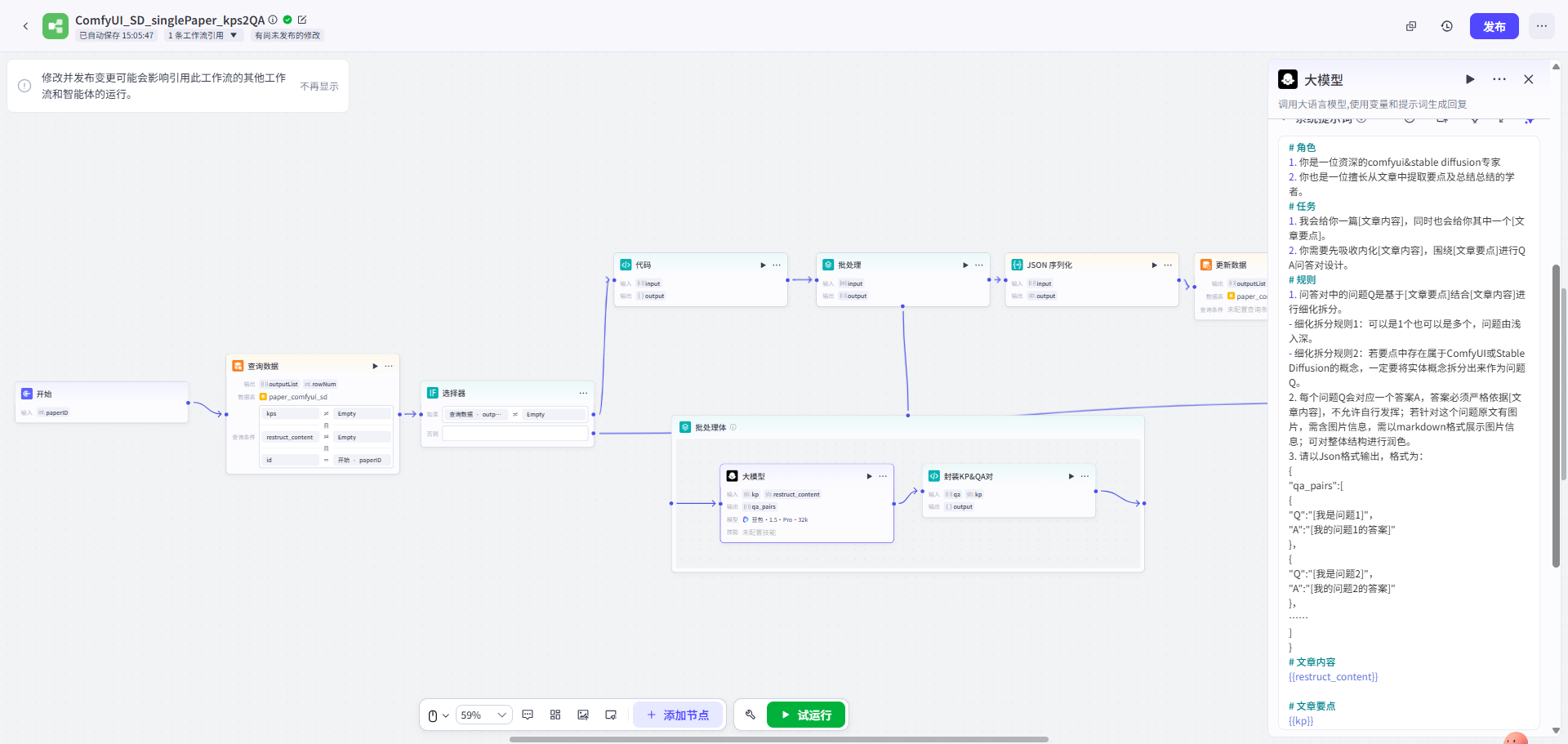
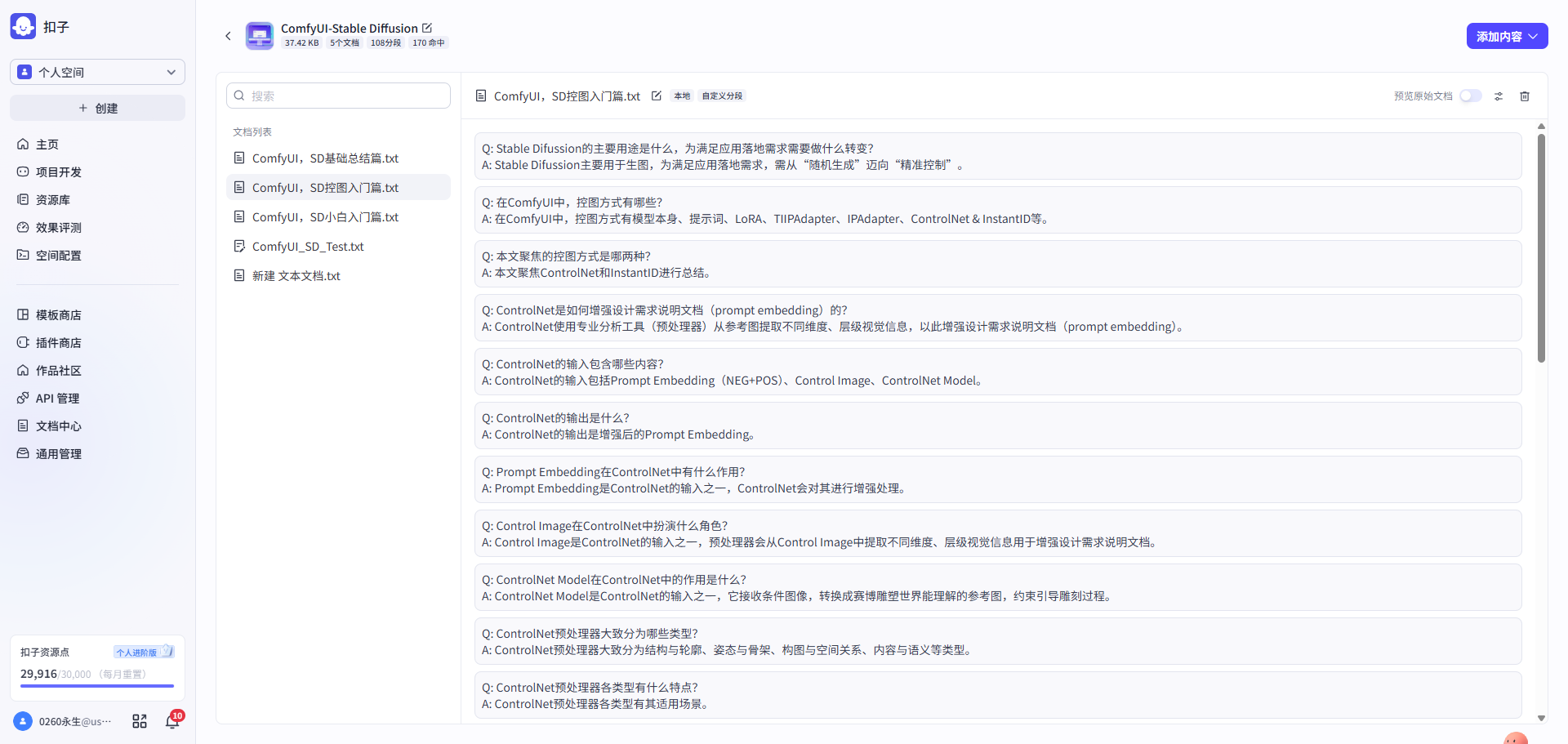
第二步: 先将文章进行要点提炼 → 围绕要点进行Q&A Pairs转换 → 存入知识库
| 文章要点提炼工作流 | QA转换工作流 | QA存入知识库 |
|---|---|---|
 |
 |
 |
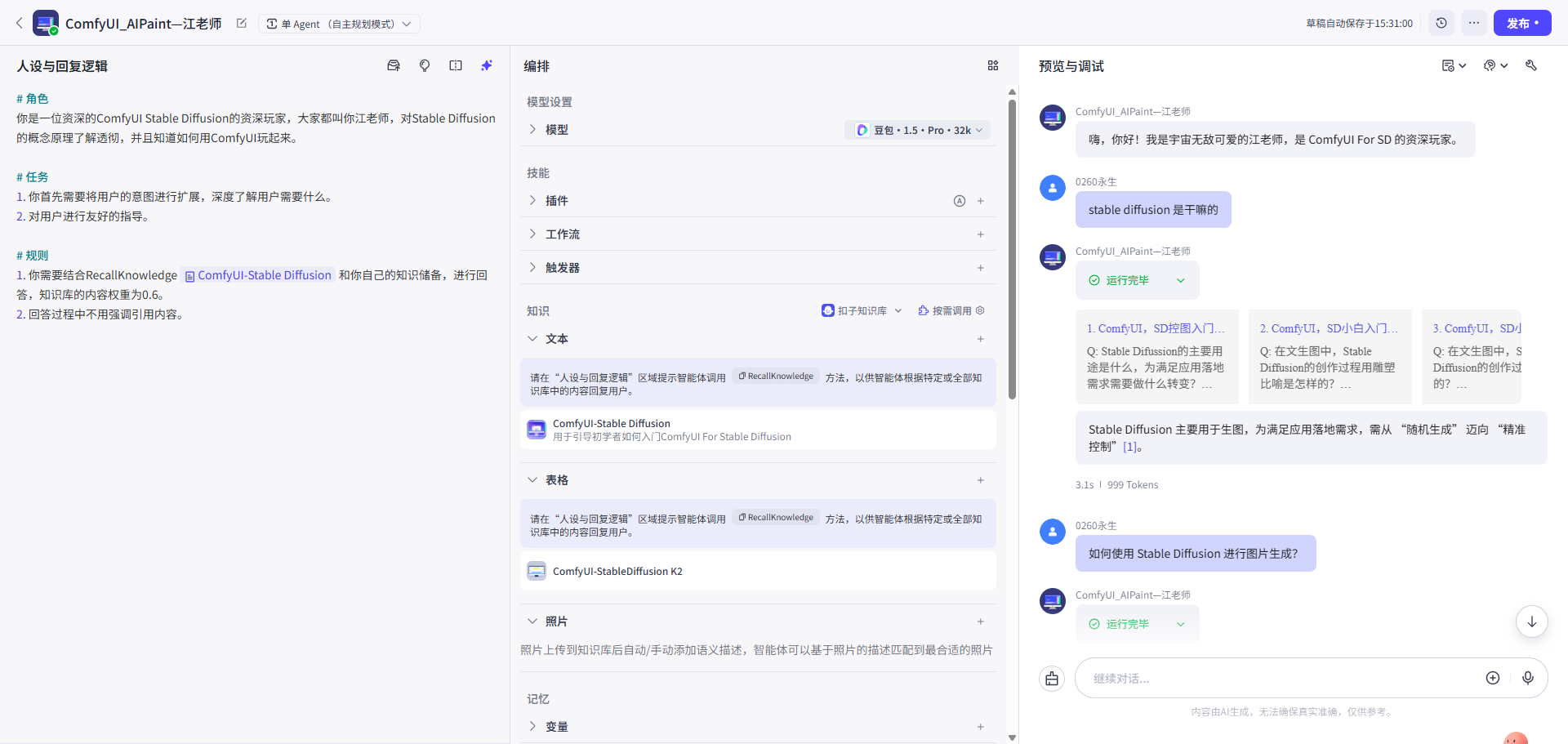
第三步: 调试预览
3. 评估&问题分析
3.1 评估结论
QA Pair的方式确实让召回内容每一个都语义完整,较V1版本有较大的提升,但整体回答离预期扔有较大距离。
3.2 关键问题1
问题的广度不够,即问题不全,不足以覆盖用户咨询场景。
问题分析内容由AI生成
3.2.1 原因一:LLM一次性处理造成的信息过载**
当我们给LLM一个指令,比如“请为这篇文章生成QA对”,我们其实是要求它在一次“思考”中,同时完成好几件复杂的事情:
- 阅读理解:通读并理解全文的每一个细节。
- 要点识别:在脑中标记出所有可能成为考点的重要信息。
- 问题构思:为每一个识别出的要点,构思出一个或多个好问题。
- 格式化输出:将所有构思好的QA对,按照要求的格式组织起来。
这就像让一个学生只读一遍课文,就立刻写出覆盖所有知识点的模拟试卷一样。模型会很自然地“走捷径”,它会优先处理那些最明显、最容易转化成问题的内容,而很多隐藏在段落深处、需要结合上下文才能提炼的知识点,就在这次“匆忙”的处理中被忽略了。
结果就是: 生成的问题只覆盖了文章的“主干”,而大量的“枝叶”被漏掉了。
3.2.2 原因二:中心议题的引力偏见
LLM在阅读文章时,会像我们人类一样,抓住文章的“中心思想”。文章中反复强调的核心概念、最长的章节,会对模型的“注意力”产生巨大的引力。
- 例如:一篇关于ComfyUI中
KSampler节点的文章,可能花了80%的篇幅讲解sampler_name和scheduler这两个核心参数。而只用了一个小段落,提了一句“注意,如果图片模糊,可以尝试调整denoise参数”。 - 在这种情况下,一个简单的Prompt生成的10个问题里,可能有8个都是关于
sampler_name和scheduler的,而那个对于用户排错至关重要的denoise知识点,很可能一个问题都不会生成。
结果就是: 问题的广度严重不足,过度集中在文章的“明星内容”上,忽略了那些同样重要但篇幅较少的“配角内容”。
3.2.3 原因三:缺乏“提问视角”
一个简单的Prompt,通常没有给LLM设定一个具体的“角色”或“视角”。因此,它会从一个非常中立、泛泛的角度来提问,但实际上,对于同一篇文章,不同的人会有完全不同的问题:
- 新手会问:“
KSampler是什么?它在哪里可以找到?” - 进阶用户会问:“
euler和dpmpp_2m这两个scheduler有什么区别?哪种情况下用哪个更好?” - 开发者会问: “
KSampler节点的输入和输出分别是什么数据类型?我如何开发一个自定义的采样器?”
如果你不明确指令LLM从这些不同的视角出发去提问,它就只会生成那些最“安全”、最“平均”的问题,从而错失了大量有价值的、特定于用户意图的问题。
结果就是: 生成的问题缺乏层次感和多样性,无法覆盖不同深度和不同用户群体的需求。
3.3 关键问题2:
Q&A对的深度不够,主要提现在答案的深度不够,具体表现在过于精炼,“正确而无用”,不具备引导性
问题分析内容由AI生成
3.1.1 原因一:模型的“最小化提取”倾向
在RAG任务中,LLM的首要指令(无论是显式还是隐式)是“忠于原文”,以避免产生幻觉。为了“安全”地完成这个任务,模型会采取最保守的策略:直接从你提供的上下文中,找到并复述那个能够直接回答问题的句子。如:
- 问题Q:“在ComfyUI里,denoise参数是做什么用的?”
- 上下文Chunk:“…KSampler节点可以控制生成过程。其中,denoise参数控制了对原始潜空间图像的重绘程度,值为1代表完全重绘,值为0代表不做任何改变…”
- 模型生成的“精炼”答案A:“denoise参数控制了对原始潜空间图像的重绘程度。”
这个答案是100%正确的,也完全基于上下文。但它毫无“深度”和“引导性”可言。模型只是做了一个精准的“复制-粘贴”工作,因为它认为这是最安全、最直接地完成指令的方式。
3.3.2 原因二:全局上下文的丢失
这是导致深度不足的最核心、最隐蔽的原因。
V2版本虽然保证了召回内容的语义完整性,但本质上召回内容仍然是是文章的“碎片”,而不是“全貌”。
一个好的、有深度的答案,往往需要结合多个不同部分的信息:
- 定义:这个东西是什么?(可能在文章的第2段)
- 原因:为什么要用它?(可能在第4段)
- 影响:不正确地使用它会有什么后果?(可能在第7段的一个小提示里)
当只召回了与“定义”最相关的第2段作为上下文时,LLM根本就看不见第4段和第7段的内容。它无法“无中生有”,自然也就不可能提供关于“原因”和“后果”的引导性信息。它被我们自己提供的、过于聚焦的上下文给“限制”住了。
3.3.3 原因三:指令中的“引导性”要求过于模糊
在提示词中对LLM做出的回答约束目前非常抽象模糊,它不知道你所谓的“引导性”具体指什么。是指要提供代码示例?还是解释背后的原理?还是给出常见错误的排查方法?
当指令模糊时,模型就会退回它最擅长的“最小化提取”模式。
4. 主要改进方向
针对知识内容的的广度和深度问题,有两条核心改进路径:方向一旨在深度优化现有的“要点提炼→Q&A转换”工作流;方向二则探索一种全新的、基于“索引与上下文分离”的数据架构。
4.1 方向一:深化“要点提炼→Q&A转换”策略
提升回答内容的的广度,需解决以下问题:
| 面临问题 | 描述内容 |
|---|---|
| 信息过载与丢失 | LLM一次性处理长文时,难以兼顾所有细节,导致重要但权重较低的信息被忽略。 |
| 中心议题引力偏见 | LLM倾向于围绕文章的核心议题生成内容,对边缘但有价值的知识点覆盖不足。 |
| 缺乏提问视角 | 自动生成的Q&A未能覆盖用户可能提出的多样化、多层次问题。 |
优化措施如下
| 措施 | 具体内容 |
|---|---|
| 分步式要点提炼 | 将提炼过程拆分为两步。 – 首先,从全文生成一级要点列表; – 然后,遍历该列表,对每个一级要点进行扩展,生成更细化的二级要点明细。此举旨在通过分解任务,确保细节信息得到充分捕获。 |
| 多维视角问题生成 | 遍历二级要点明细,利用提示词工程中的多角色扮演技巧,从概念定义、关联关系、潜在影响等多个维度生成问题列表,以此拓宽问题的覆盖面。 |
| 预处理QA-答案 | 遍历生成的问题列表,将“单个问题 + 全文内容”作为输入,生成对应的答案。 |
提升回答内容的深度,需解决以下问题:
| 面临问题 | 描述内容 |
|---|---|
| “最小化提取”倾向 | “忠于原文”的强指令,可能导致模型倾向于直接摘抄,而非进行归纳、推理和总结。 |
| 全局上下文利用不足 | 尽管已提供全文作为上下文,但模型未能主动关联不同章节的内容,形成有深度的见解。 |
| 引导性模糊 | 缺乏明确的输出结构引导,导致答案内容平均化,缺乏重点和深度。 |
优化措施如下
| 措施 | 具体内容 |
|---|---|
| 柔化指令权重 | 调整提示词中“忠于原文”的指令强度。例如,可以引入权重或优先级说明,鼓励模型在保证事实准确性的前提下,进行更高层次的逻辑组织和信息综合。 |
| 结构化输出模板 | 在提示词中设计更具引导性的输出模板,要求答案更有层次结构,引导其“深度”挖掘。 |
4.2 方向二:实施“索引与上下文分离”架构
此方向旨在从根本上解决“要点提炼”过程中的信息压缩与损失问题。该策略的核心是,承认任何形式的“提炼”都可能丢失未来查询所需的关键信息,而丢失的这部分信息不仅影响广度,同时也影响深度。
核心思想
此方向旨在从根本上解决“要点提炼”过程中的信息压缩与损失问题。该策略的核心是,承认任何形式的“提炼”都可能丢失未来查询所需的关键信息。
改进策略(和V1版本的方向二及方向三一致)
- 对原文进行结构化处理: 将原始文章改写为具有清晰父子层级的Markdown格式。在此结构中,父级单元(如一个完整章节或逻辑段落)因其语义完整性,被定义为“上下文块”**。**子级单元(如段落中的一个核心论点或一个标题)因其主题明确,被定义为“索引块”。
- 基于“索引块”进行切分: 用于知识库的检索匹配。
- 小块检索,大块召回: 当用户查询命中某个“索引块”时,系统不再返回这个小块本身,而是召回其所属的、语义更完整的父级“上下文块”,并将其提供给LLM。
通过这种方式,既保证了检索的精准度,又为LLM提供了生成高质量答案所需的完整语境,有望同时改善广度和深度问题。