1. V4版本内容
在《Rag Agent,迭代史(三)》_V3版本的基础上为召回上下文增加topic(主题描述)元数据,即:通过对Chunk进行主题预抽取的方式,得到主题列表”,LLM基于主题列表先进行大纲制作再参考上下文进行回答,以此降低割裂感。
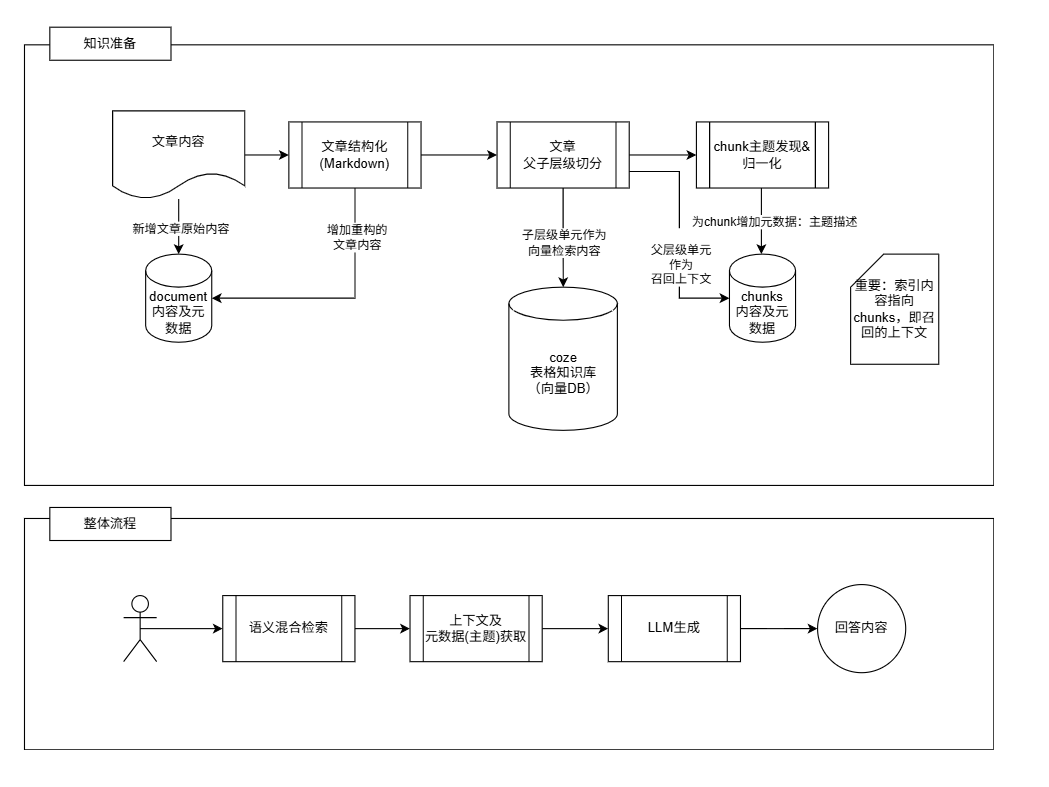
[!NOTE]coze自带的知识库将作为简化的向量数据库,本版本及以后,知识库仅作为语义检索使用。
2. 执行步骤
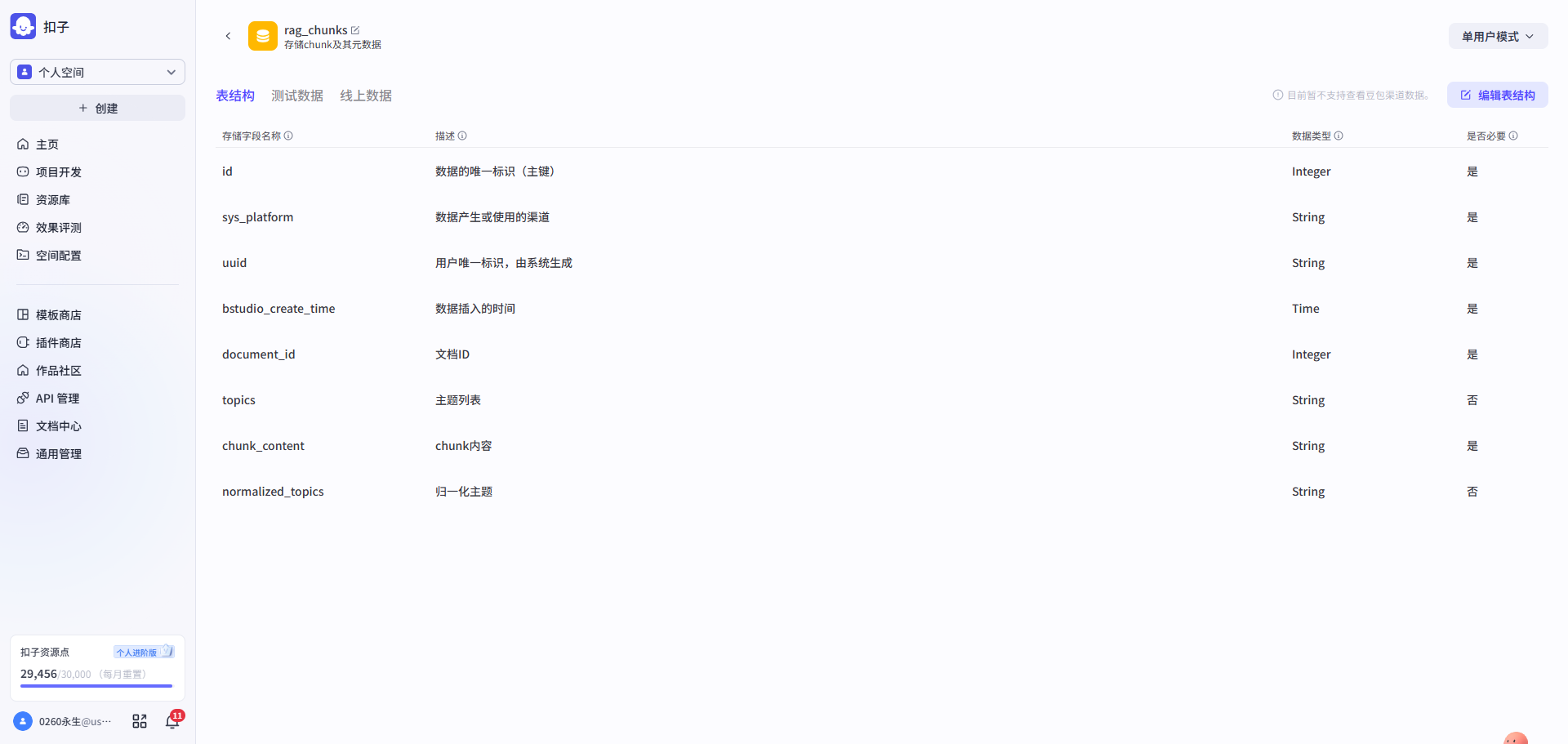
第一步: 设计document表 → 设计chunks表 → 准备向量数据库(coze知识库)
| 设计document表 | 设计chunks表 | 准备向量数据库(coze知识库) |
|---|---|---|
 |
 |
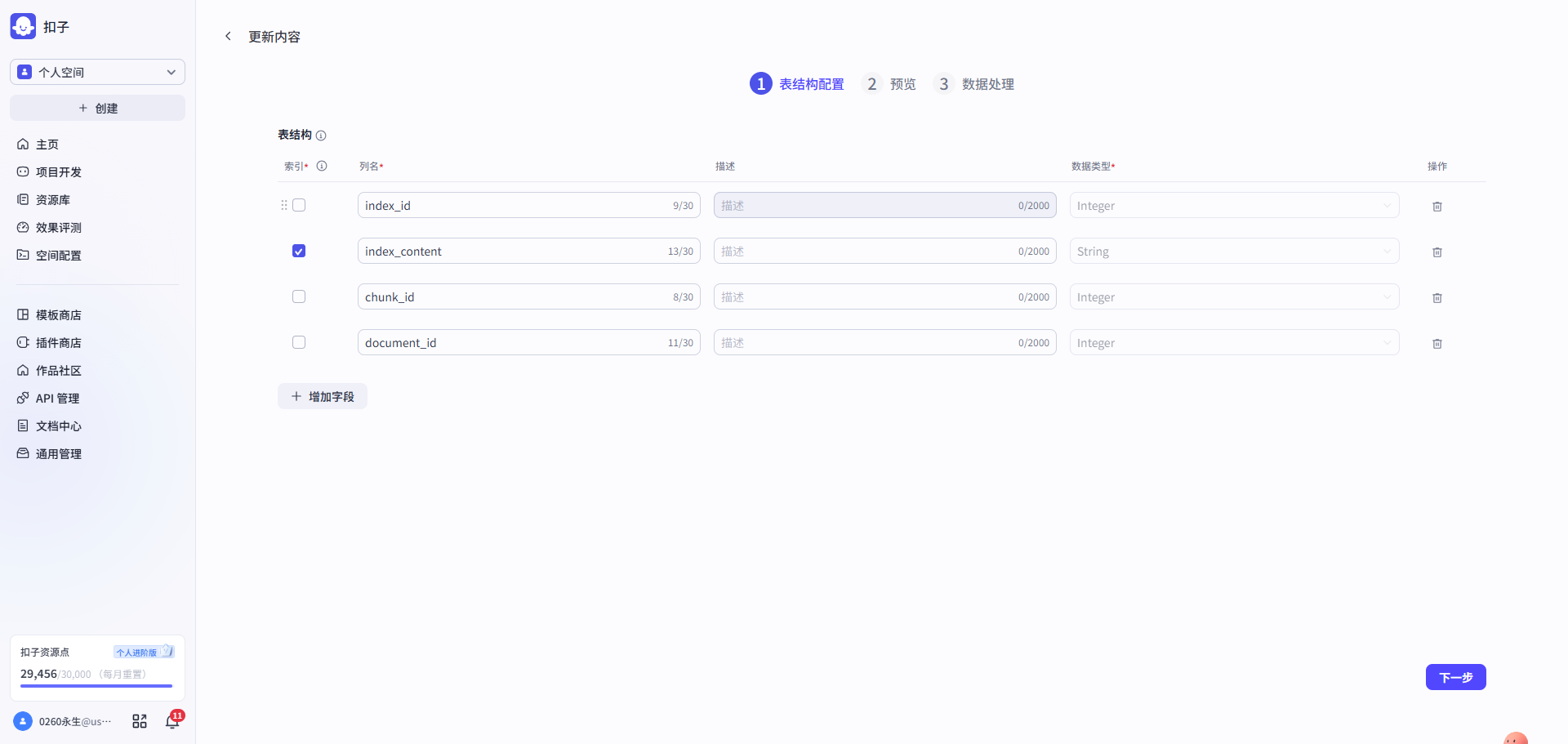 |
| 用于记录文章原始内容、重构化的内容及其元数据 | 文章语义分段后,将父层级单元(上下文)存入chunks表,并记录相应的元数据 | 用coze自带的表格类型知识库近似替代,文章语义分段后,将子层级单元(索引)存入该库,并记录元数据,此版本的元数据主要是指document_id和chunk_id,指向文章和chunks(上下文)。 |
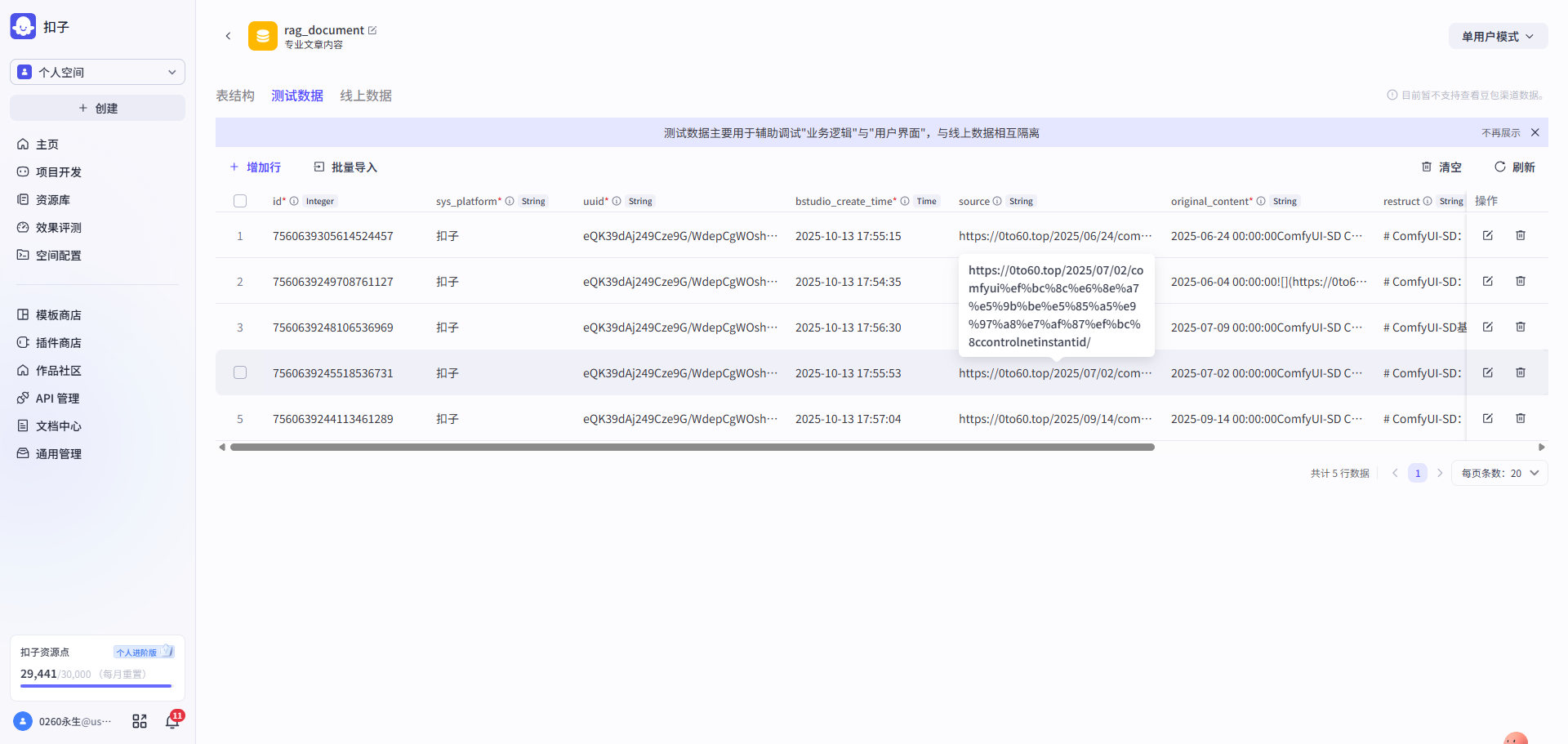
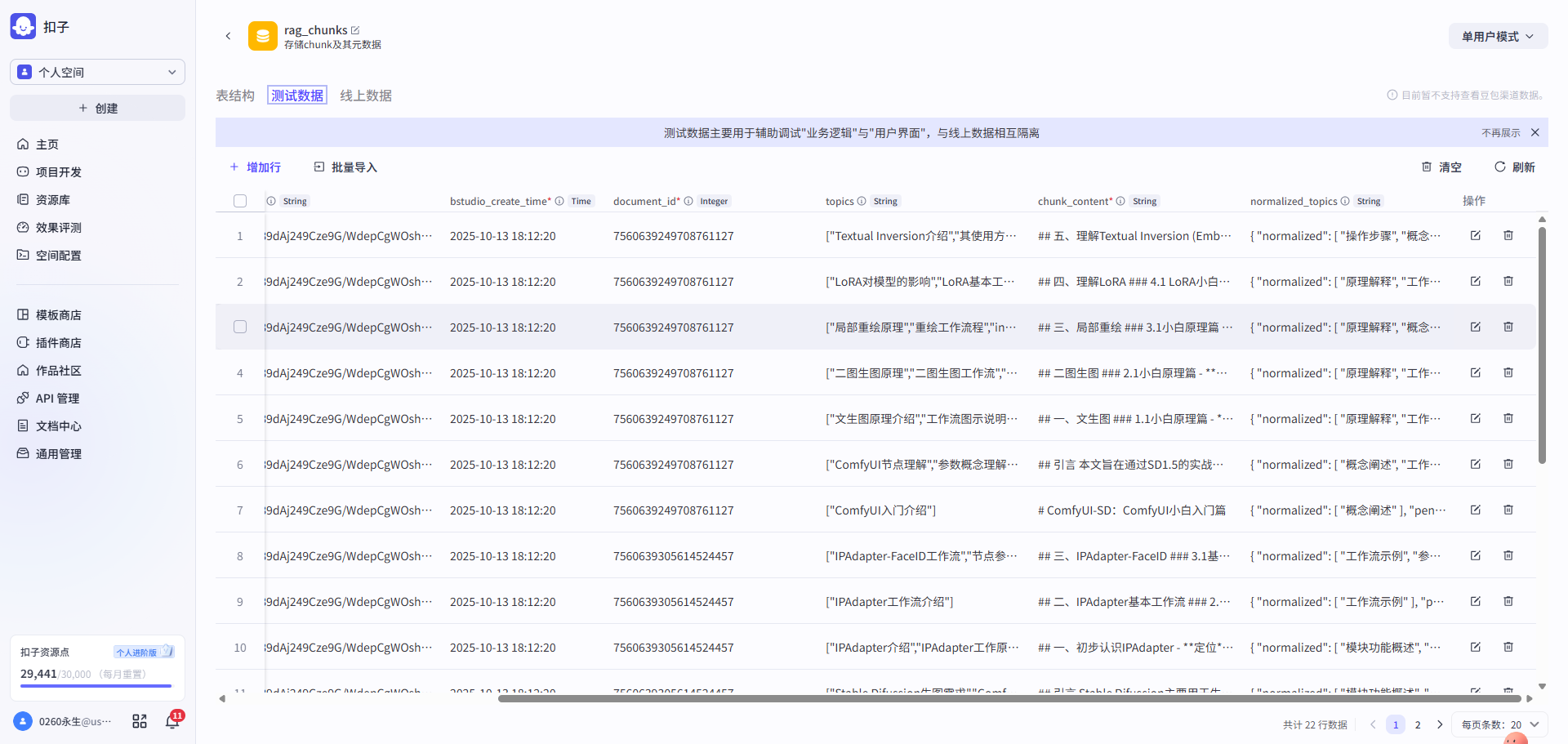
第二步: 文章内容迁移 → 导入chunks内容 → 导入index向量索引表内容
| 文章内容导入 | 导入chunks内容 | 导入index向量索引表内容 |
|---|---|---|
 |
 |
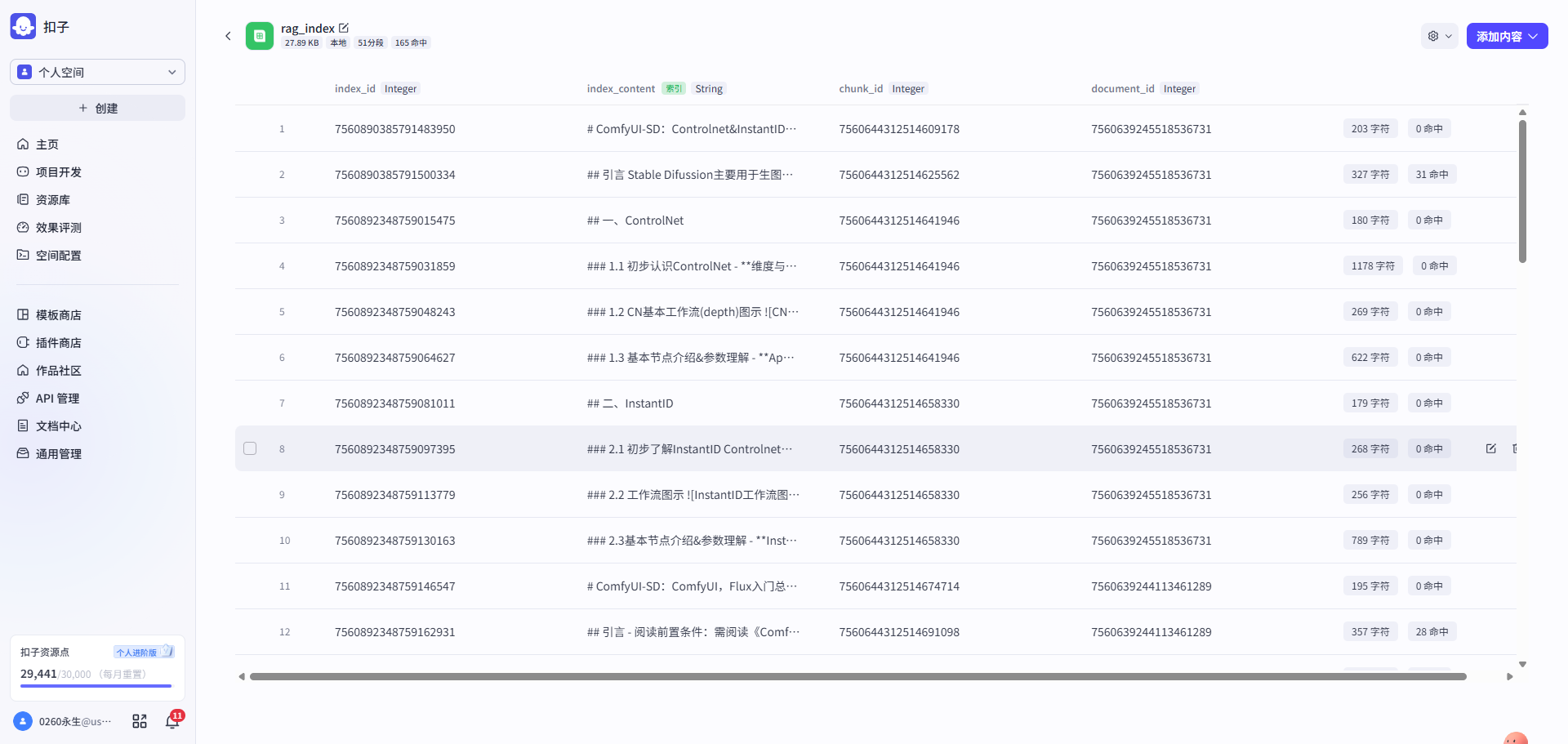 |
| 将V3的文章内容导入到文章document表 | 即新增父层级单元内容,其会被作为上下文召回给到LLM | 即新增子层级单元内容,其将会被作为向量检索的索引 |
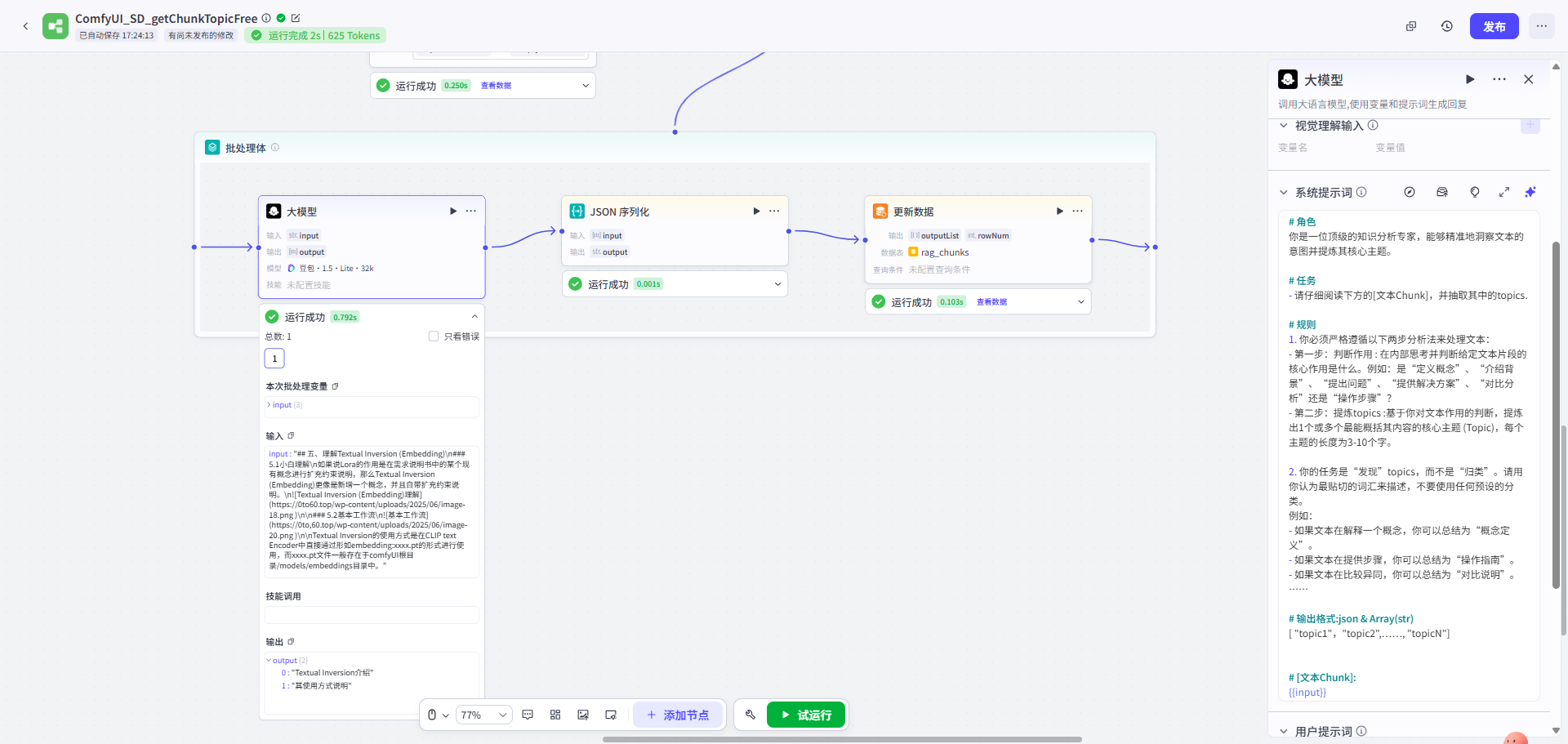
第三步: 遍历提取每一段chunk的自由主题信息 → 主题归一化处理
| 遍历提取chunk的自由主题信息 | 主题归一化 |
|---|---|
 |
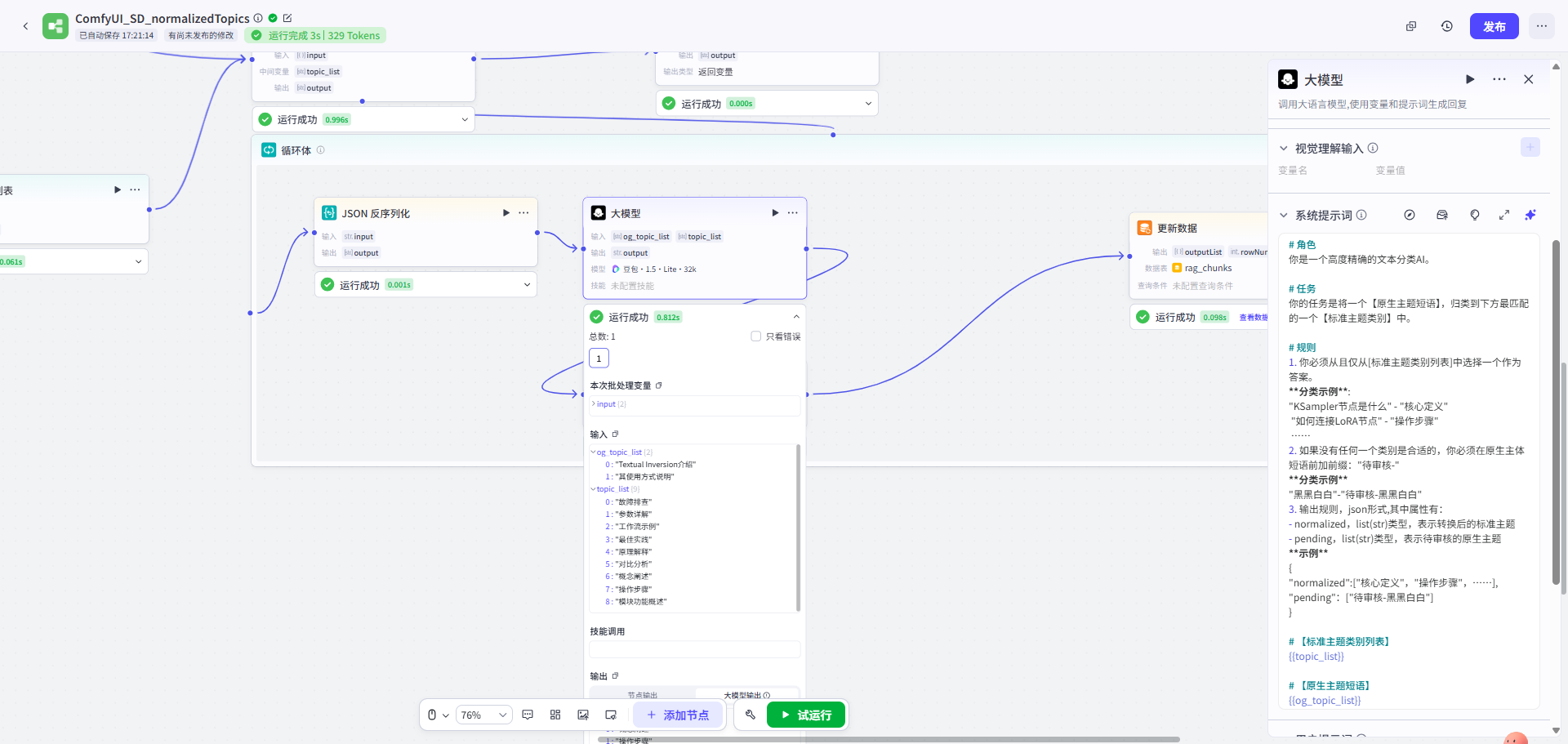 |
| 先对每一段chunk进行自由主题信息的提取 | 基于提取的自由主题,进行归一化处理 |
第四步: 创建工作流-知识库检索 且 获取chunks(上下文)及其元数据(主题信息)
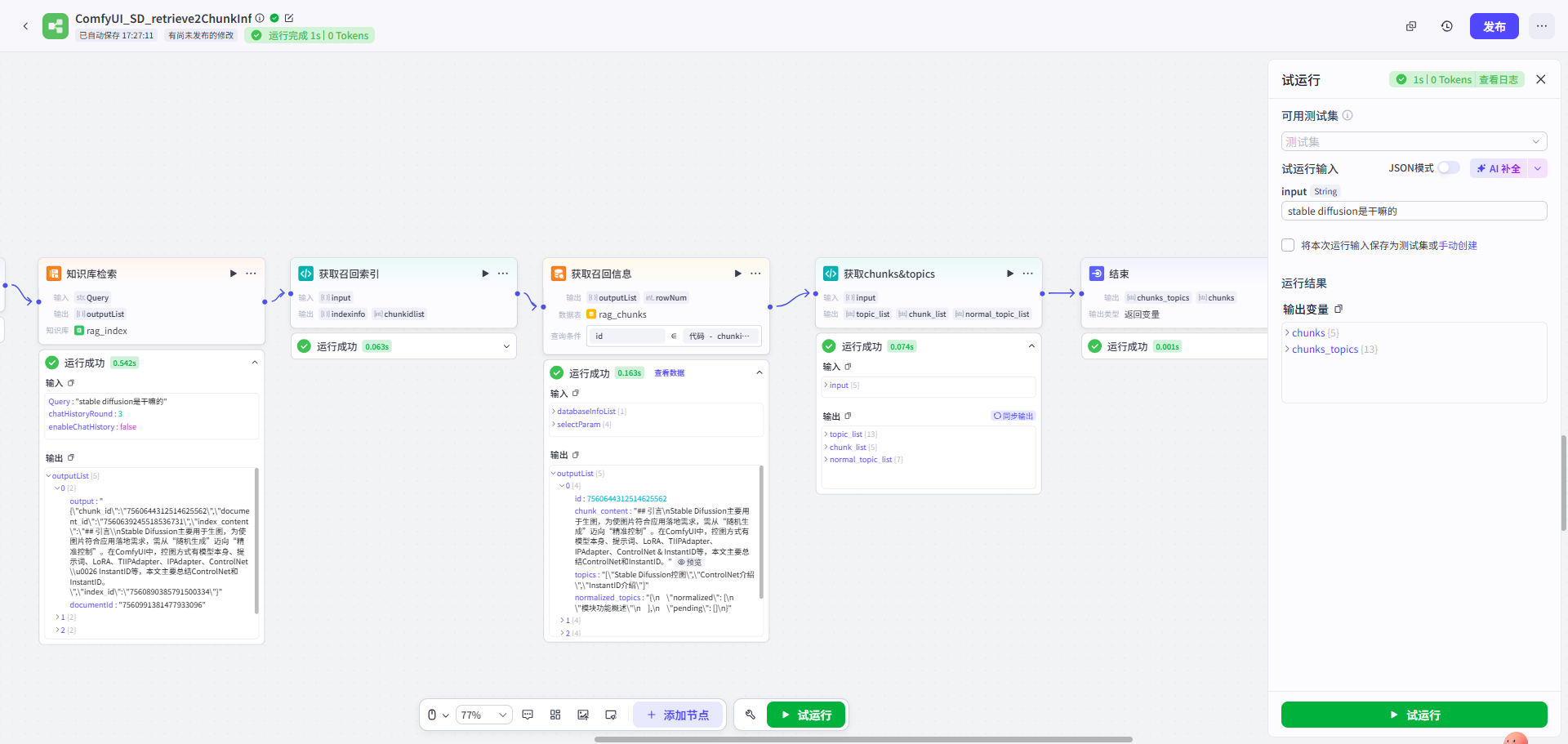
检索召回工作流图:知识库检索→获取chunks(上下文)及其元数据(主题信息)
第五步: Agent设置,提示词和工作流配置
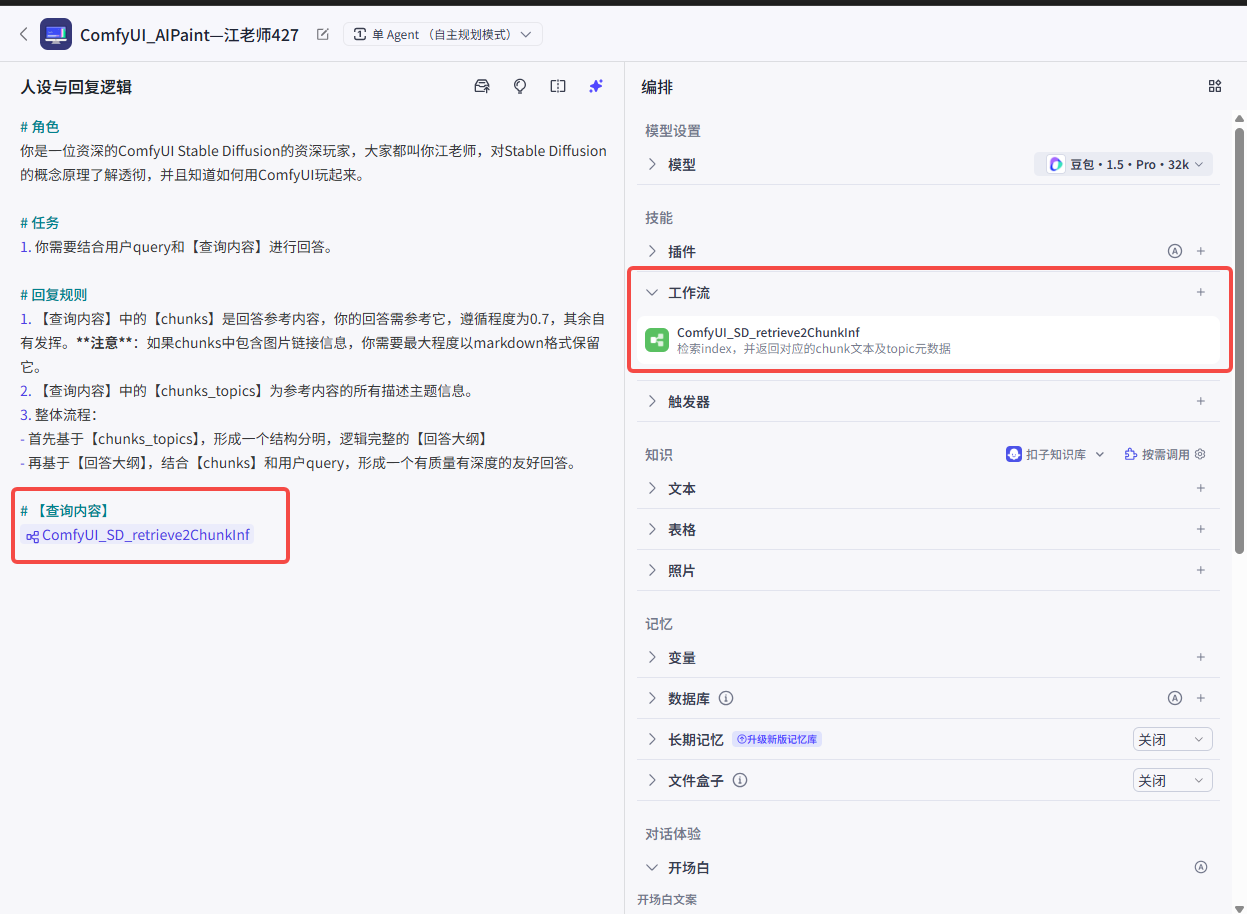
Agent设置:提示词和工作流配置
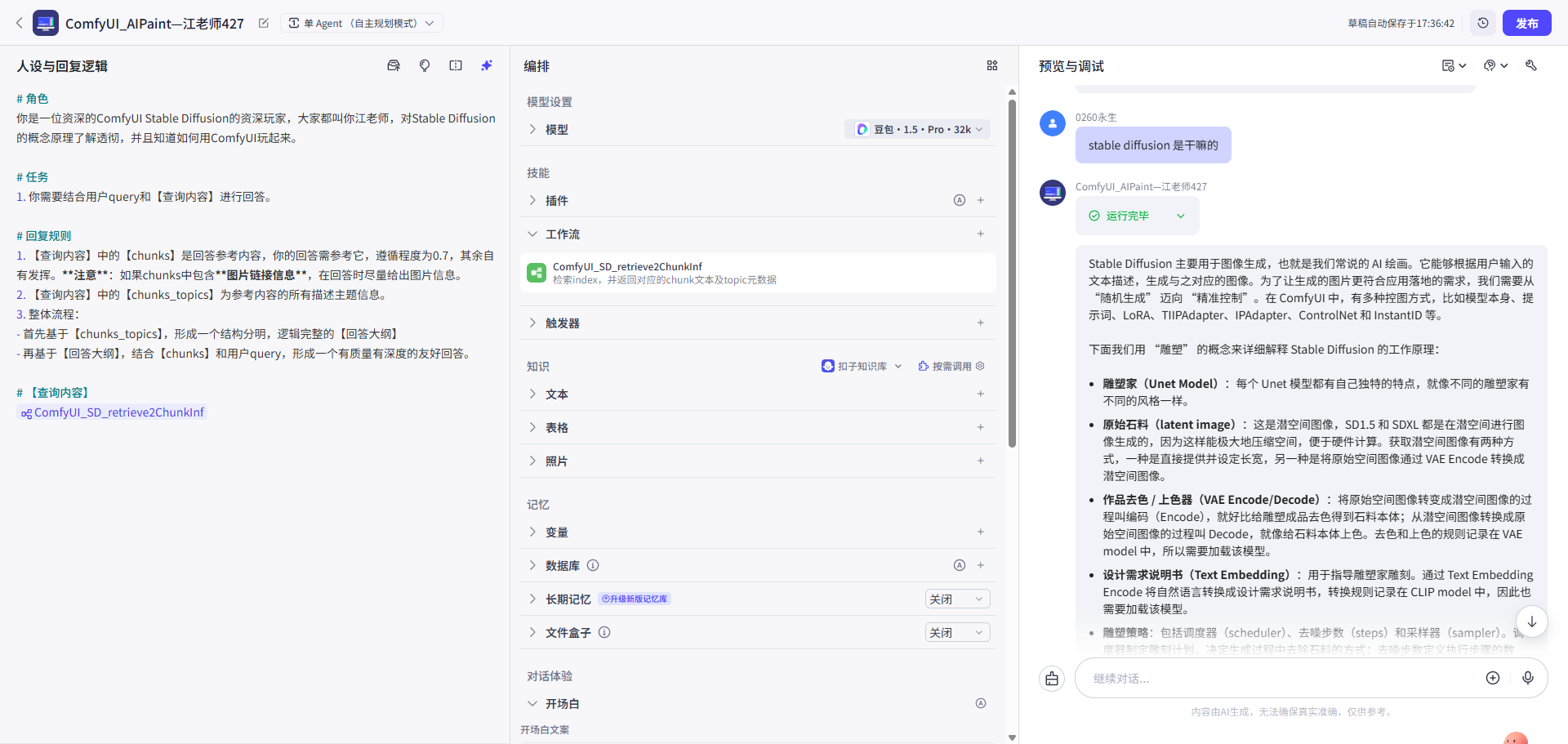
第六步: 预览调试
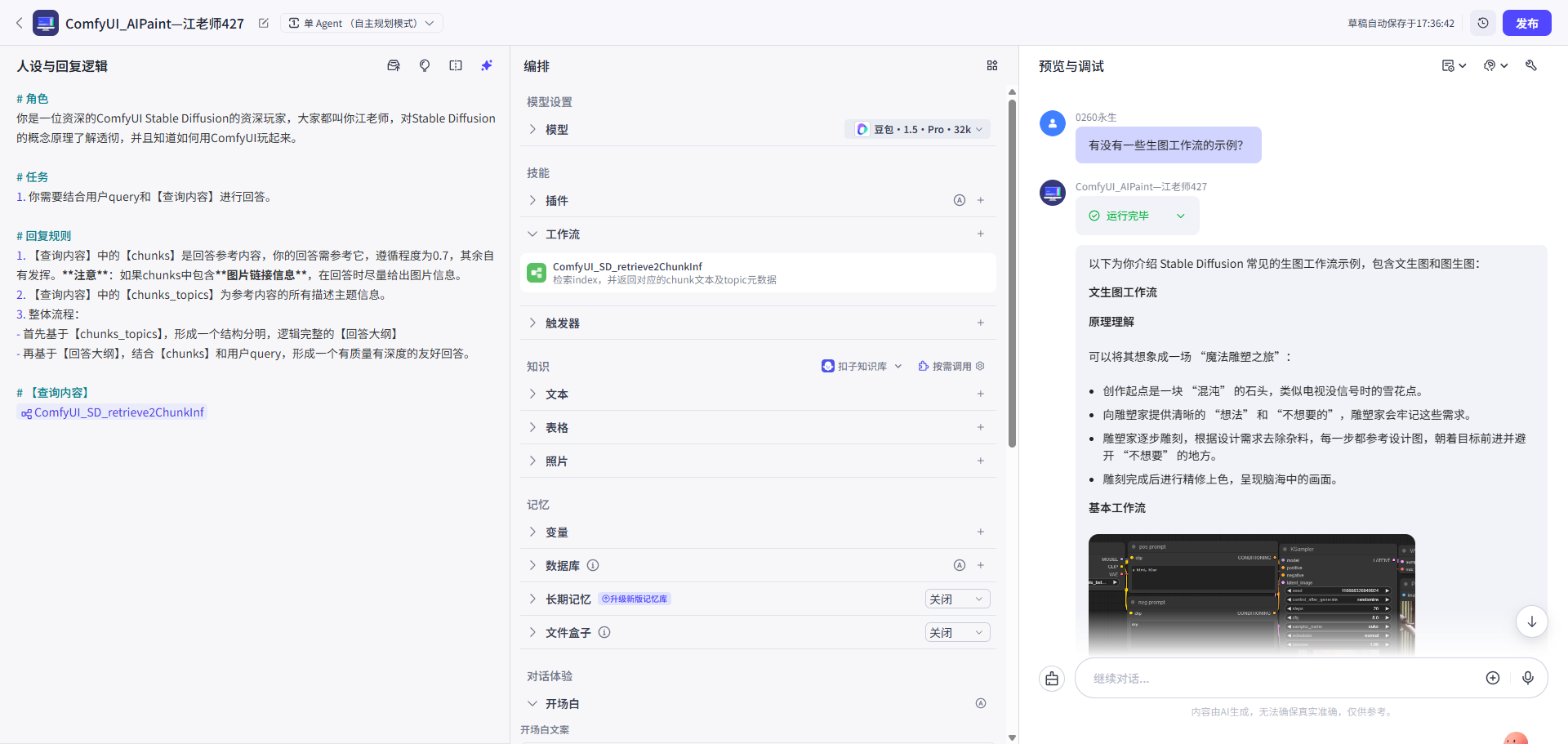
| 预览调试1:纯文 | 预览调试2:回答带图 |
|---|---|
 |
 |
3 评估&问题分析
3.1 评估结论
核心功能已达预期:
基于上下文的“动态大纲生成”策略(先生成大纲,后生成内容)效果显著。它为LLM提供了清晰的生成脚手架,极大降低了回答内容的逻辑跳跃和“割裂感”,提升了阅读体验。
次要发现:
直接使用LLM生成的“自由主题”比“归一化主题”在生成大纲时表现更好。
- 自由主题包含的语义更为丰富。
- 个人认为归一化的主题信息适用于两个方向:1)一些严谨的领域不需要创意,比如法律、医疗等领域,可以使用归一化的主题生成大纲。2)归一化的主题信息可作为逻辑筛选条件,为程序处理提供便利。
3.2 关键问题
在评估中发现了一个比“答案结构”更底层的问题: 召回内容不准确或不全面。
具体表现为:系统经常召回与查询词高度相似的“干扰项”,反而过滤掉了措辞不同但包含正确答案的文档。
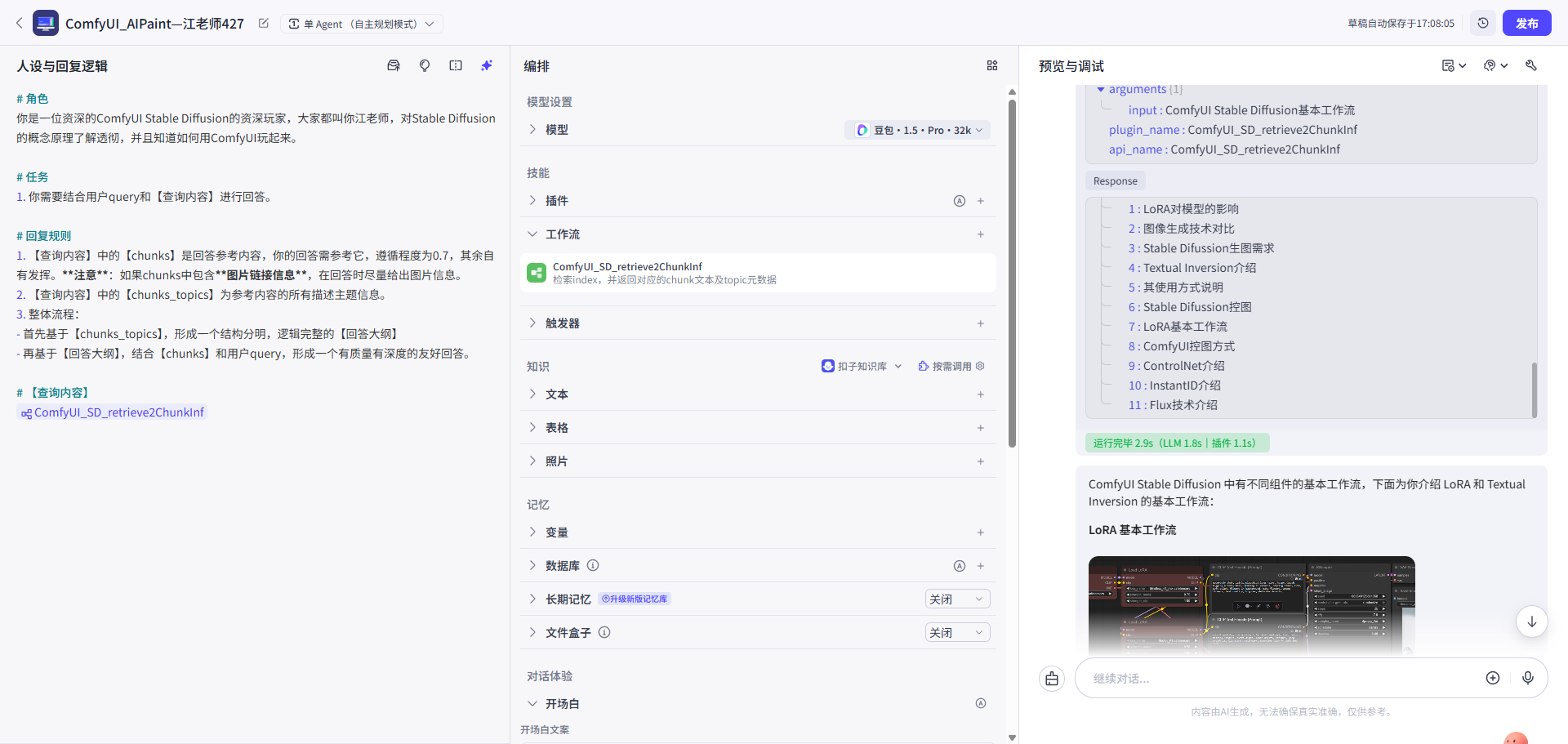
召回内容不准或不全
问题分析内容由AI生成
3.2.1 原因:相关性陷阱
你遇到的不是简单的数量问题,而是一个更深层、更棘手的“相关性陷阱” (Relevance Trap) 问题。这是所有RAG系统都会遇到的最经典、最痛苦的问题之一。
问题的核心是:向量相似度高的,不等于对用户最有用的。
系统召回了它认为“语义上最像”的内容,但这些内容可能是“正确的废话”或者“看似相关但答非所问”的干扰项,反而把那个措辞不同但真正能解决问题的答案给挤掉了。
为什么会掉入“相关性陷阱”?
让我们来诊断一下,为什么一个“特别像”的错误答案,其相似度得分会高于一个“不那么像”的正确答案。
- “表面文本”的胜利 (Surface-level Textual Similarity)
- 场景:用户问:“如何安装
ComfyUI-Manager?” - 陷阱:知识库里有一篇写得很好的通用教程,标题是“新手必看:如何安装任何自定义节点”,里面用了大量“安装”、“节点”、“文件夹”等词汇。它的用词和用户的提问高度重合。
- 被过滤掉的正确答案:另一篇专门讲
ComfyUI-Manager的文档,可能标题是“Manager节点的进阶用法与故障排查”,它可能花了很多篇幅讲如何更新、解决冲突,只有一小部分讲安装。 - 结果:对于Embedding模型来说,那个通用的、表面文字更匹配的教程,其向量相似度得分可能高达
0.92,而真正有用的那篇,得分可能只有0.88。如果你设置了top_k=1或者阈值卡得很高,正确答案就被无情地过滤掉了。
- 场景:用户问:“如何安装
- 通用模型的“领域知识盲点” (Domain Knowledge Blind Spot)
- 通用的Embedding模型是在海量互联网数据上训练的。它知道“安装”和“节点”是相关的,但它并不知道
ComfyUI-Manager是一个极其特殊且重要的实体。它无法像你一样,给这个特定的名词赋予更高的权重。它只是把它当作一个普通的、由几个字母组成的词。
- 通用的Embedding模型是在海量互联网数据上训练的。它知道“安装”和“节点”是相关的,但它并不知道
4. 改进方向
既然问题的本质是向量检索的内在缺陷(即“相关性陷阱”),那么改进必须围绕“提升召回的精准度”和“丰富召回的维度”来展开。
4.1方向一:优化Embedding策略
换模型,换向量维度。
- 换模型: 尝试更换为针对特定领域精调过的Embedding模型。
- 换维度: 调整向量维度,寻找更适合当前数据量和复杂度的表征空间。
4.2 方向二:提高召回率
此为“兜底”策略。承认第一阶段检索的局限性,通过扩大召回数量来保留正确答案进入下一阶段的机会。
- 扩大Top-K: 在Rerank(重排序)机制之前,将初步检索的top_k从(例如)3提升到15。
- 目标: 确保“不那么像但正确”的答案能有机会进入Rerank阶段,用更精细的Rerank模型将其打捞上来。
4.3 方向三:查询改写
既然知识库与用户查询(Query)的表述存在“鸿沟”,那么可以尝试改写Query来匹配知识库。
具体操作: 利用LLM将用户的单个原始问题,扩展或转义为多个具有不同表述、不同侧重点的子问题,然后进行多路检索并合并结果。
4.4 方向四:强化混合检索,引入NER
向量检索既然存在内在缺陷(”相关性陷阱”),那就引入事实检索策略进行互补和强化。
- 问题: 传统的“关键词检索 + 向量检索”通常以“或”逻辑简单合并,虽然提升了召回率,但引入的关键词噪音反而可能拉低语义的精准度。
- 方案升级: 引入NER作为高级的“事实检索”手段。
可以这样理解NER,可以对关键词检索进行升级,为每个检索目标预提取关键词,这个关键词主要表式实体概念,而这些实体概念与其他实体概念又能建立某种关系,比如从属、因果、使用、同义等,让检索目标与检索目标间接产生关联关系。这样就能按照实体关键词精确找到检索目标,又能按照实体关系,找到相关检索内容,丰富召回的上下文。
NER的核心价值(以下是AI回答内容):
- 绝对精确性与歧义消除 (Precision & Disambiguation)
- 对比关键词: 关键词检索“model”会返回所有包含该字符串的文档。
- NER方案: NER在预处理时就能识别出不同语境下的“model”,并打上结构化标签(如
entity: Checkpoint或entity: LoRA)。在检索时,系统可以根据查询上下文(如“加载一个SD1.5的model”)执行基于实体的精确过滤,只召回与Checkpoint相关的文档,从根本上消除歧义。
- 赋能关系推理 (Relationship-based Reasoning)
- 向量检索的局限: 面对“IPAdapter和ControlNet可以一起使用吗?”这类问题,向量检索最多只能找到同时包含这两个词的文档,但无法理解它们之间的关系(如是并联、串联还是冲突)。
- NER方案: 在预处理时,NER识别出
IPAdapter和ControlNet为两个节点实体,而关系提取 (RE) 进一步识别出它们之间存在CONNECTS_TO(连接)或CONFLICTS_WITH(冲突)的关系。 - 查询革命: 检索查询因此可以从“模糊的文本相似度搜索”升级为“精确的图数据库查询”:“请找到那些同时包含
**IPAdapter**和**ControlNet**实体,并且这两个实体之间存在**CONNECTS_TO**关系的知识单元。”