引言
本文的目的是通过SD1.5的实战记录,从而理解ComfyUI中各节点的作用,以及加深对各种参数及概念的的理解。
一、文生图
1.1 小白原理篇
Stable Diffusion 的魔法雕塑之旅
你是不是常常幻想,如果能把脑海中的画面直接变成一幅画,那该有多好?现在,有一种叫做 Stable Diffusion 的魔法,它就能帮你做到这事!
别担心,这不是什么高深的电脑程序,你可以把它想象成一位拥有特殊能力的雕塑家,而你要做的,只是提供你的想法和雕塑规则。
魔法的起点:一块“混沌”的石头
当你想雕塑一个东西时,雕塑家会给你一块特定大小,但表面粗糙、充满随机纹理的原始石头。这块石头上没有任何具体的形状,看起来乱七八糟的,就像电视没信号时的雪花点一样。
这块混沌的石头,就是 Stable Diffusion 开始创作的起点。
你的设计需求说明:清晰的“想法”和“不想要的”
然后,你会把你的设计需求说明交给雕塑家。这份设计图非常特别,它不仅描述了你想要雕塑成什么样子(比如“一只可爱的蓝色猫咪,坐在阳光下的窗台上”),还会清楚地标注你不希望出现什么(比如“不要模糊的,不要有文字,不要扭曲的肢体”)。
雕塑家会把这些设计需求说明上的想法,牢牢地记在心里。
神奇的雕刻过程:一点一点去除杂料
接下来,真正的魔法来了!雕塑家会动手雕刻。
他不是一下子就把作品变出来,而是一步一步、一刀一刀地进行。每一次下刀,他都会小心翼翼地根据你的设计需求说明,判断哪些是多余的“杂料”,然后将它们去除。
这个过程会重复很多很多次。刚开始时,他可能只是粗略地去除大块的杂料,让雕塑有个大致的轮廓。随着雕刻的进行,他会越来越精细,去除微小的杂料,雕琢出细节、纹理和光影。
而且,每一次下刀,雕塑家都会不断地参考你的设计图:
- “这块泥土是不是离我想要的蓝色猫咪更近了?”
- “这部分雕刻会不会让它看起来扭曲?”
他会努力让每一次下刀都朝着你设计图上描述的那个方向前进,同时也要避开你说“不想要”的地方。
最后的润饰:让作品栩栩如生
当雕塑家觉得雕刻步骤差不多完成时,他会对作品进行最后的精修上色,最终呈现出你脑海中那幅真实的画面。
牢记这个比喻,我们将带着类似的想法去理解SD文生图的逻辑。
1.2 基本工作流图示
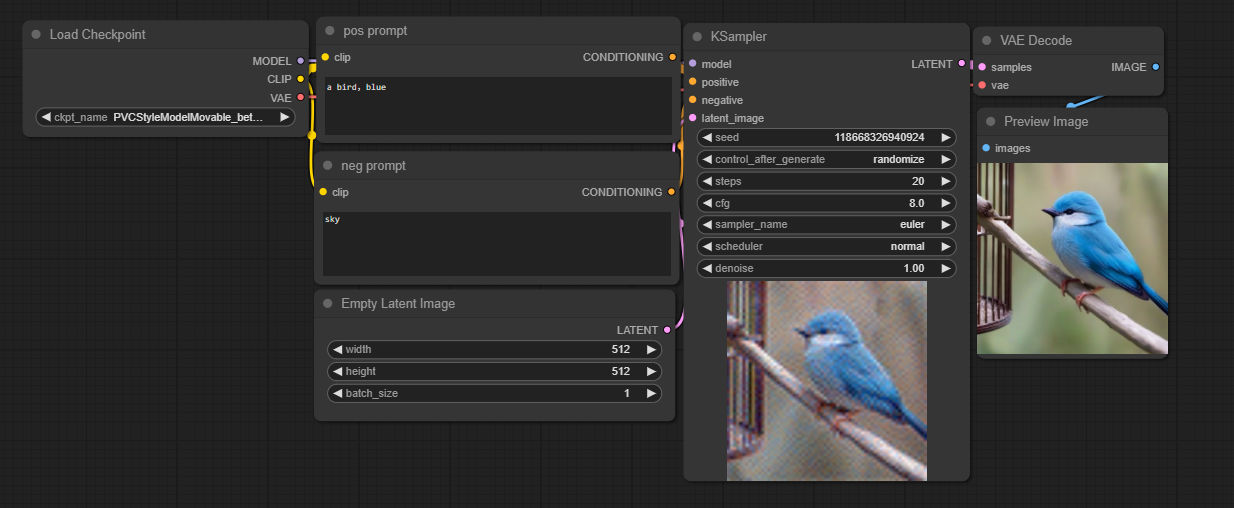
节点名称 | 雕塑描述 |
|---|---|
load checkpoint | load checkpoint会做以下几件事:
输入:一个打包的 输出: 1. 雕塑家(model) 2. 最后的精修上色方式(VAE Decoder) 3. 设计需求文档转换器(CLIP Text Encoder) |
CLIP TEXT Encode | 刚才说了,雕塑家是不认可咱们的语言,ta们有属于赛博雕塑家世界专有的语言。 咱们可以用自己能力理解的语言进行描述想要什么(positive prompt)和不想要什么(negtive prompt),通过雕塑家(model)认可的转换器(CLIP Text Encoder),就能得到雕塑家所需的雕塑设计需求说明文档(Text Embeddings),所以: 输入端: 1. 接收一个指定的转换器(CLIP Text Encoder),通常直接由load checkpoint节点得到 2. 输入咱们的要求 输出: 设计需求说明文档(Text Embeddings,节点中也成为Conditionning) |
Empty latent Image | 雕塑首先得有一块初始石料,这个石料,而选择石料的时候,会首先确定大小,所以先拿个筛选器 输入:宽高width、height 输出:石料大小筛选器(empty latent img) |
KSampler | 有了雕塑家和设计需求说明文档,雕塑家就可以按照自己的各种技巧开始进行雕刻 1. 确定一个初始石料:拿着木框筛选器,带着指定的令牌(seed)找到对应的石料并线将大小处理好(得到初始噪声latent)。 2. 基于雕塑家自身的特性和风格,选择合适的技巧和工具(sampler_name,scheduler),确定大概要雕刻多少次(steps) 3. 每次雕刻时时,都要对比着设计需求说明文档(Text Embeddings)来判断是否符合需求,而我们可以要求雕塑家遵循设计需求说明文档的严格程度(CFG) 4. 雕完后,得到一个石料本色的雕塑(未上色) 输入:雕塑家、设计需求说明书(Text Embeddings,节点中也成为Conditionning,分pos和neg),石料大小筛选器(empty latent img),具体是石料(seed),雕刻技巧(sampler_name,scheduler),雕刻次数(steps)及说明文档遵循程度(CFG) 输出:一个雕刻好的石像 |
VAE Decode | 有了石像后,准备上色,这时我们需要知道上色方式是什么。 输入:雕刻好的石像(kSamler的输出latent),上色方式(load chekpoint的输出VAE) 输出:栩栩如生的雕像(VAE Decode的输出img) |
Preview Image | 雕像展示柜 |
1.3 KSampler参数理解
参数名 | 雕塑理解 | 加深理解 | 图示 |
|---|---|---|---|
seed(随机种子) | 就好比你从仓库里挑选了一块特定纹理和初始形状的随机石料。每次用同一个 seed,你拿到的都是那块一模一样的石料。如果你换一个 seed,就拿到了另一块完全不同的随机石料。在雕塑中的作用: 决定了你的雕塑的初始基础形态。即便有相同的设计图纸(prompt),不同的石料(seed)最终雕刻出的雕塑也会有各自的特点。 | 一个整数值,用于初始化“随机石料”的初始状态。相同的 seed 值,在其他所有参数不变的情况下,每次运行都会生成相同的初始随机噪声图像。 | 其他参数不变,不同seed的结果  其他参数不变,相同seed的结果  |
control_after_generate | 好比你雕刻完一个作品后,决定下一件作品要用什么样的石料:
在雕塑中的作用: 控制你每次雕刻实践中“石料”的选取策略,方便你批量尝试或固定实验条件。 | 这个参数决定了在一次生成完成后, seed 值的行为
| |
steps(去噪步数) | 就是你雕刻的总刀数/雕刻动作的总次数。
在雕塑中的作用: 决定了雕刻的精细程度和完成度。 | 定了 UNet 将噪声图像去噪的迭代次数。每次迭代都代表一次去噪步骤。步数越多,图像去噪越充分,细节通常也越丰富,但生成时间也越长。 | 看上去步数到达一定程度后,不会有太大的区别,可能和调度器和采样器本身有关系  |
cfg(提示词相关性) | 雕刻家在雕刻时对“设计需求说明”的遵守程度。
在雕塑中的作用: 决定了雕塑对“设计需求”的还原度与自由发挥之间的平衡。 | 控制图像生成时,模型对文本提示词(text embedding)的“遵循”程度。
|  |
sampler_name(采样器名称) | 雕刻时所使用的“雕刻手法”或“工具套路”。
在雕塑中的作用: 决定了雕刻过程的效率和最终作品的风格特点。 | 决定了在去噪过程中,UNet 如何在每一步去噪时预测和移除噪声的具体算法。不同的采样器有不同的数学特性,会影响生成速度、图像质量和风格。常见的有 Euler, DPM++ 2M Karras, DDIM 等。 | |
scheduler(调度器) | 决定了你雕刻每一刀的“力度”和“去除杂料的速度曲线”。
在雕塑中的作用: 影响了雕刻过程的节奏和效率,以及最终作品的精细度。 | 这是一个与 sampler_name 紧密相关的参数,它决定了去噪过程中每一步“噪声量”的衰减方式(也就是去噪步长)。不同的调度器可以优化采样过程,有时能用更少的步数达到更好的效果。例如 karras, normal, exponential 等。 | |
denoise(去噪强度) |
在雕塑中的作用: 决定了你的雕塑在多大程度上要“忠于”原始石料的形态(如果你是在已有的雕塑上修改),而不是完全从零开始。 | 这个参数主要用于图生图 (Image-to-Image) 任务,而不是纯粹的文生图。它决定了在将输入图像编码到潜在空间后,向其添加多少噪声。
|
1.4 Sampler、Scheduler & Steps的理解
1.4.1. Sampler (采样器):雕刻的手法/工具
- 原理:
- 采样器决定了在去噪的每一步中,如何从当前带噪的图像状态 xt(当前的“带泥土的石料”)和 UNet 预测出的噪声 ϵθ(xt,t,c)(雕塑家预测哪些是“杂料”)中,推导出下一步更清晰的图像状态 xt−1(去除一部分杂料后的石料)。
- 你可以把它理解为“去噪算法”或“迭代更新规则”。它定义了每次“下刀”的具体数学操作。
- 不同的采样器使用了不同的数学方法来估计和移除噪声,因此它们在收敛速度、稳定性、生成质量和计算成本上有所差异。
- 常见类型和特点:
- 确定性采样器(Deterministic Samplers):
- Euler: 最简单,每一步的去噪是确定的,相同输入每次结果都相同。速度快,但可能需要更多步数才能达到好的效果。
- DPM++ 2M Karras: 非常流行和高效的采样器。它结合了 DPM-Solver 和 Karras 调度器的思想,通常能在相对较少的步数下生成高质量的图像,效果通常比 Euler 更平滑细腻。
- DDIM (Denoising Diffusion Implicit Models): 也是确定性的,可以用于生成和反演(将图片转为噪声)。
- 随机性采样器(Stochastic Samplers):
- Euler A (Ancestral): 在每一步去噪时会添加少量的随机噪声。这使得每次运行即使使用相同的
seed和steps,结果也会略有不同,增加了多样性。通常能生成更“生动”或有“颗粒感”的图像。 - DPM++ SDE Karras: SDE (Stochastic Differential Equation) 意味着它在每一步中也引入了随机性。
- Euler A (Ancestral): 在每一步去噪时会添加少量的随机噪声。这使得每次运行即使使用相同的
- 确定性采样器(Deterministic Samplers):
- 雕塑比喻:
- 它就像雕塑家所掌握的各种雕刻手法或工具套路。
- Euler 可能是基础的“刀法”,简单直接。
- DPM++ 2M Karras 可能是更高级、更精细的“雕刻技巧”,能更快地达到光滑、完美的表面。
- Euler A 就像在每一步雕刻时,雕塑家会稍微撒点“魔法粉尘”,让雕塑的细节带有一些随机的、意想不到的美感。
1.4.2. Scheduler (调度器):雕刻的节奏/力度曲线
- 原理:
- 调度器决定了在整个去噪过程中,噪声去除的“时间表”或“力度曲线”。它定义了在不同的
steps下,模型应该去除多少噪声,以及噪声水平如何从高(初始)到低(最终)逐步衰减。 - 通俗地讲,它控制了去噪过程的“非线性步进”。例如,它会决定在早期阶段去除更多的噪声,还是在后期阶段更精细地处理。
- 不同的调度器算法会影响去噪过程的稳定性、收敛速度和最终图像的质量。
- 调度器决定了在整个去噪过程中,噪声去除的“时间表”或“力度曲线”。它定义了在不同的
- 常见类型:
- karras: 非常流行的调度器,通常与 DPM++ 采样器结合使用。它使用一种优化的噪声调度曲线,使得模型在较少步数下也能生成高质量的图像,效果通常更平滑。
- normal: 均匀地分配去噪步长。
- exponential: 噪声去除的速度呈指数衰减。
- sgm_uniform (SDXL 常用): 针对 SDXL 模型优化的调度器。
- 雕塑比喻:
- 它就像雕塑家雕刻每一刀的“力度”和“节奏”安排。
- karras 调度器可能意味着雕塑家一开始大刀阔斧,去除大量杂料,然后随着雕塑逐渐成型,他会越来越轻柔、越来越精细地打磨,这种力度和节奏的变化是经过优化的。
- normal 调度器就像雕塑家在每一刀都用差不多的力度,均匀地去除杂料。
1.4.3. Steps (步数):雕刻的总刀数/雕刻的次数
- 原理:
- Steps 就是去噪迭代的总次数。UNet 会在每一步中预测噪声,然后采样器会根据这个预测来更新图像状态。这个过程会重复 Steps 次。
- 步数越多,去噪过程越充分,理论上图像会越清晰,细节也可能越丰富。
- 然而,并非步数越多越好。达到一定步数后,收益会递减,甚至可能引入伪影(artifacts)或过度平滑。
- 常见实践:
- 对于大多数 1.5 模型和现代采样器(如 DPM++ 2M Karras),通常 20-30 步就能获得很好的效果。
- 对于 SDXL,可能需要 25-35 步。
- 步数越少,生成速度越快,但图像质量可能下降。
- 雕塑比喻:
- 就是你雕刻的总刀数或者总的雕刻动作次数。
- Steps = 10:可能只雕了10刀,作品很粗糙。
- Steps = 30:雕了30刀,作品已经非常精细。
- Steps = 100:雕了100刀,可能在30刀时就已经很好了,再多雕也没有明显提升,甚至可能过度打磨。
1.4.4. 三者之间的关系
它们是相互协作的:
- Sampler (手法) 决定了如何下刀。
- Scheduler (节奏) 决定了在哪些阶段下重刀,哪些阶段下轻刀。
- Steps (总刀数) 决定了下刀的总次数。
- Sampler 与 Scheduler 的协同:
- 许多采样器(特别是 DPM++ 系列)是专为与 karras 调度器配合使用而设计和优化的。当它们一起使用时,通常能在更少的 steps 下达到更好的效果。
- 错误的组合可能会导致效率低下或生成质量不佳。
- Steps 对 Sampler 和 Scheduler 的影响:
- Steps 的数量直接影响 Sampler 的迭代次数和 Scheduler 的“时间分配”。
- 如果 Steps 太少,无论采样器和调度器多优秀,都可能没有足够的时间去噪,导致图像质量差。
- 如果 Steps 太多,可能会浪费计算资源,且不一定能带来显著的质量提升。
- CFG Scale 的额外影响:
- CFG Scale 决定了采样器在每一步去噪时对提示词的“听话程度”。它会影响采样器判断“噪声”的方向,从而改变去噪路径。高 CFG 通常会和更多的 steps 结合使用,因为模型需要更多步数来严格遵循提示。
1.4.5. 推荐搭配
万金油搭配(推荐度:★★★★★)
- Sampler (采样器): dpmpp_2m_karras (ComfyUI 中通常显示为 DPM++ 2M Karras)
- Scheduler (调度器): karras
- Steps (步数): 20 – 30 步 (建议从 25 步开始尝试)
- CFG Scale (额外推荐,非直接搭配): 6.0 – 8.0 (建议从 7.0 开始尝试)
为什么推荐这个搭配?
- dpmpp_2m_karras 采样器: 这是一个非常高效和高质量的采样器。它结合了 DPM-Solver 和 Karras 调度器的优点,通常能在相对较少的步数内生成平滑、细节丰富的图像,且收敛性好。
- karras 调度器: 这个调度器是专门为 DPM++ 系列采样器优化的。它能智能地分配去噪步长,使得在去噪过程中,噪声去除的节奏更合理,从而在有限的步数下达到更好的效果。
- 20-30 步: 在这个搭配下,25 步是一个非常平衡的值,通常能提供很好的质量和较快的生成速度。对于大多数需求而言,再增加步数可能收益不大,反而增加生成时间。如果你想要更多细节或在某些情况下出现伪影,可以稍微增加到 30 步;如果想追求速度,可以降低到 20 步。
- 6.0-8.0 CFG Scale: 这个范围是比较通用的,能让模型较好地遵循你的提示词,同时保留一定的创造性。
追求多样性/轻微颗粒感 (推荐度:★★★★☆)
如果你想在生成的图像中获得一点点随机的变化,或者偶尔喜欢那种略带“噪点”或“颗粒感”的艺术效果:
- Sampler (采样器):euler_ancestral (ComfyUI 中通常显示为 Euler A)
- Scheduler (调度器): karras (或 normal 也可以,但 karras 通常更通用)
- Steps (步数): 20 – 40 步 (建议从 30 步开始尝试)
- CFG Scale: 6.0 – 9.0 (可以稍微提高一些,因为 Euler A 的随机性)
为什么推荐这个搭配?
- Euler A 采样器: 这是一个随机采样器,它在每次迭代中会引入微小的噪声。这意味着即使 seed 和其他参数完全相同,每次生成的图像也会有细微的不同,增加了探索性。它的图像风格有时会显得更“自然”或“手绘感”。
- 更多步数: Euler A 通常会受益于更多的步数,以充分发挥其随机性并细化图像。
二、图生图
2.1 小白原理篇
在“文生图”的魔法世界里,我们是从一块未经雕琢的“混沌石料”开始创作,一切都是从零到有。
但如果你的任务是对一件现有作品进行“二次创作”或“修改”呢?比如,你手头已经有一尊精美的雕塑,但想给它换个材质,或者让它摆出不同的姿势,甚至变成另一种完全不同的生物?
别担心,这同样是 Stable Diffusion 的拿手好戏——“图生图”。这个过程其实并没有你想象中那么复杂,它仅仅在开始雕刻前,多加了两个巧妙的“魔法动作”。
第一步:魔法“去色”与“重塑”
你提供的“现有作品”(无论是照片还是画作),在进入魔法世界的第一件事,就是经历一次奇特的“魔法去色”。
你可以把这理解成,雕塑家会施展一个特殊的魔法,瞬间将你提供的彩色、生动的作品,变回一件只有“基本形状和模糊轮廓”的原始石料。这块石料不再有色彩,也不再有精细的纹理,就像回到了雕塑的“草稿”状态。
为什么要做这个动作?
在这个魔法世界里,雕塑家(也就是我们的模型)最擅长的“雕刻动作”总是在那种没有最终上色的“草稿石料”上进行的。直到最后一步,他才进行精修上色。这个“去色”的过程,其实是为了把你的现有作品,先转换成模型最熟悉、最容易进行“去噪”雕刻的“草稿”形式。这样做也能大幅降低计算量,让魔法效率更高。
第二步:涂上“创作的泥巴”
接下来,就是为你的“二次创作”争取创作空间的时候了。
雕塑家会在这块刚刚被“魔法去色”的石料表面,均匀地“涂抹”上一层额外的“泥巴”。这层泥巴会重新带来一些随机性和混沌感,就像在光滑的表面上重新覆盖了一层待处理的材料。
你涂的“泥巴”越多,覆盖得越厚,那么原作品的痕迹就会被掩盖得越深,雕塑家后续创作的自由度就越大,最终作品与原作品的差异也可能越大。
如果你只涂薄薄一层“泥巴”,那么原作品的轮廓和细节就会若隐若现,雕塑家就会更忠实于原作品进行精修或微调。
这个“涂抹泥巴”的多少,就决定了你希望对原作品进行多大程度的“大刀阔斧”改造。
第三步:重回“文生图”的起点,开始新的创作!
完成了这两个“魔法动作”——先魔法去色,再涂上创作的泥巴——你的“半成品”雕塑就又回到了一个充满随机混沌但又带有原始痕迹的“草稿石料”状态。
从这一刻起,整个“雕刻过程”就和“文生图”一模一样了!雕塑家会根据你新的“设计需求说明”(你希望它变成什么样子,不希望它出现什么),一步一步地去除多余的“泥巴”,精雕细琢,最终呈现出一件既有你原始作品的影子(如果泥巴涂得少),又融入了你全新创意的精美作品!
2.2 基本工作流图示
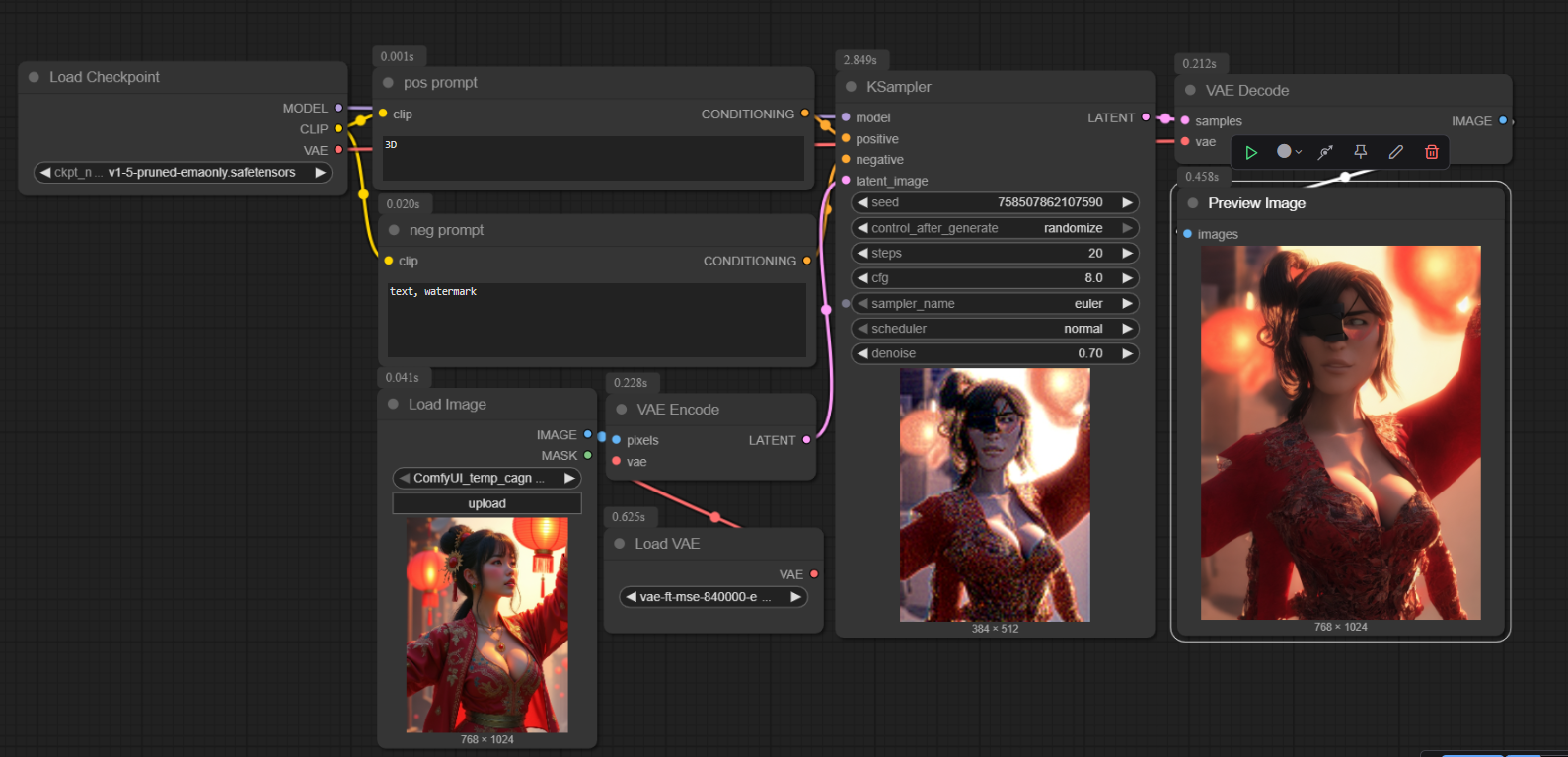
相对于文生图的基本工作流,多了Load Image,Load VAE 和 VAE Encode
节点名称 | 雕塑描述 |
|---|---|
Load Image | 将现有作品拿出来 |
Load VAE | 确定魔法去色应该使用哪一种方式(VAE 模型),值得一提的是,每一种方式同时确定了魔法去色(VAE Encode)和上色(VAE Decode)的技巧。 |
VAE Encode | 当确定了去色方式时,就执行去色动作(VAE Eecode)。 输入:现有作品(Image) 和 去色方式(VAE模型) 输出:去色后的作品(image latent) |
2.3 再次理解denoise(denoising_strength)
这个参数通常被翻译成去噪强度,但是我更愿意将其理解成加噪强度,或者我更愿意将其翻译成重塑幅度,其越大,重塑的空间越大。因为涂的泥巴越多,原有作品对雕塑过程的约束就越少。

三、局部重绘
3.1 小白原理篇
文生图,从一块混沌石料,遵循设计需求说明文档进行创作。
图生图,则从一件现有作品进行重塑,需要先进行魔法去色,再遵循设计需求说明文档进行创作。
而inpaint,则是不仅需要对现有作品进行魔法去色,还需选定重塑区域,再遵循设计需求说明文档进行创作。
第一步:”确定改造重塑区域”并整体”魔法去色”
同样要拿出那件“现有雕塑”,需要用一张特殊的“魔法遮罩”(mask),精确地圈选出你想要改造的“局部区域”,告诉雕塑家:“我只动这一块地方,其他地方尽量别动!”。然后让它经历“魔法去色”(VAE encode),回归“草稿石料”的状态。
第二步:再改造重塑区域涂上“创作的泥巴”
雕塑家只会聚焦在被你圈选出的“魔法遮罩区域”内,根据你设定的“改造程度”(Denoise),重新“涂抹上额外的泥巴”。遮罩之外的区域,则会小心翼翼地保持原样,不被泥巴覆盖。
第三步:重回“文生图”的起点,开始新的创作!
完成局部准备后,雕塑家便会在这块“被涂抹泥巴”的“局部草稿”上,根据你针对这个“局部”提供的新的设计需求说明书(Prompt),开始精准的雕刻。最神奇的是,他在雕刻时,不仅会严格按照你新的局部要求,还会确保新雕刻的部分,能完美、自然地融入到作品未被触碰的其他部分中,不留下任何突兀的痕迹。
3.2 基本工作流图示
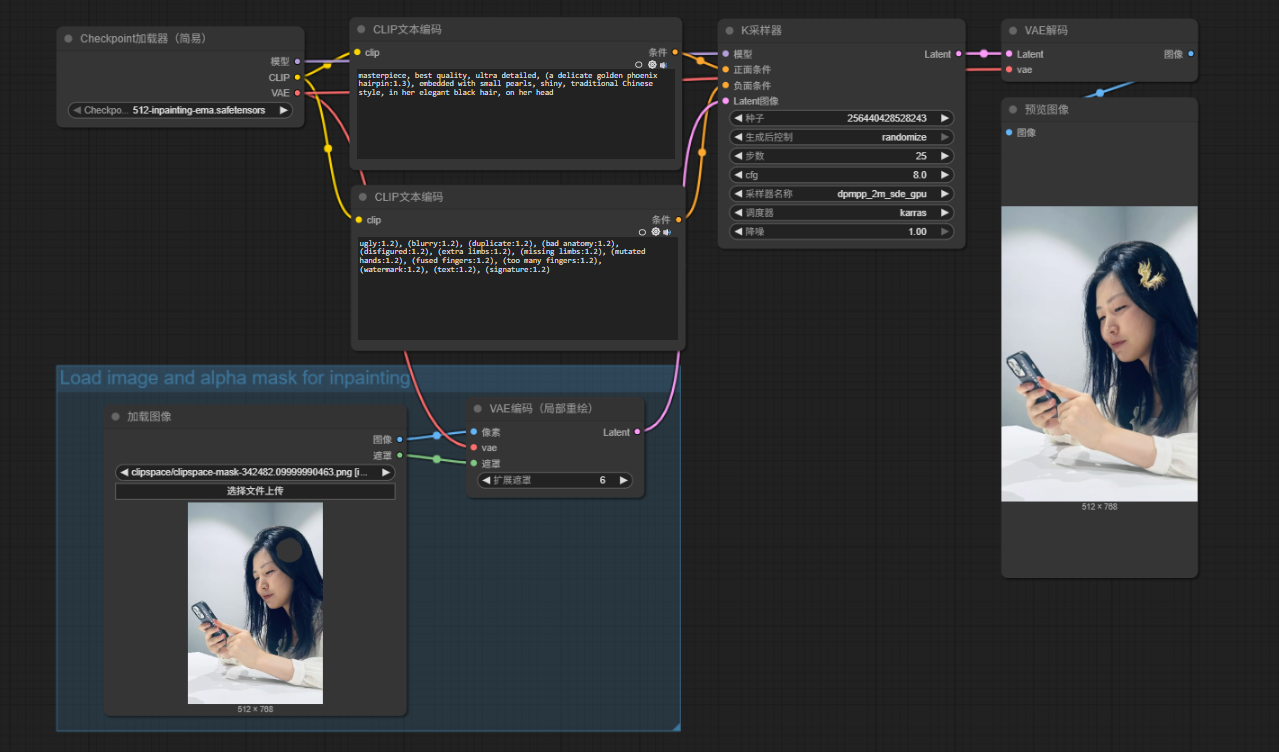
相对于图生图的工作流,增加了遮罩信息,同时VAE Encode节点也作了调整,VAE Encode(for inpaint)
节点名称 | 雕塑描述 |
|---|---|
Load Image | 将现有作品拿出来,并且在Mask Editor中圈选需要重绘的区域 |
VAE Encode(for inpaint) | 接收已圈选区域的雕塑(original image和mask),并对其魔法去色(将其融合到同一个latent中)。 |
Ksampler | 基于重绘幅度(denoise),先在取色的雕塑上在圈选的区域进行摸泥巴,然后再机 |
3.3 加深理解inpaint
整个过程:
3.3.1 Load Image 和 Mask Editor
当你在 Load Image 节点加载图片后,通过 mask editor 工具,你创建了一个像素级的二值遮罩 (pixel-level binary mask)。这个遮罩通常是黑白图,白色区域表示要修改的区域(遮罩),黑色区域表示要保留的区域。
3.3.2 VAE Encode (魔法去色) 和 mask 的整合:
没错,当原始图像(image)和这个像素级的 mask 一起被送入 VAE Encode 节点(或专门的 Inpaint 编码器)时:
- 图片被编码: 原始图片(像素数据)会被 VAE 的编码器部分转换成潜在空间图像 (latent image)
- Mask 被编码或调整: mask 本身也会被处理。最常见的做法是:
- Mask 也被 VAE 编码器处理成潜在空间中的 mask: VAE 编码器不仅会编码图像,也会将像素级的 mask 压缩并转换成对应潜空间尺寸的 mask。这个潜空间 mask 的分辨率会比像素级的低,但仍然表示了被遮罩的区域。
- Mask 可能被放大/缩小后作为额外的通道: 有些实现会将潜空间 mask 作为潜在图像的一个额外的通道(例如,如果潜图像是 4 通道,它可能变成 5 通道,第 5 个通道就是 mask 信息)。
- Mask 可能会影响潜在图像的初始化: 或者,mask 会在潜在图像初始化时,指导某些区域的加噪和不加噪。
3.3.3 KSampler (雕刻过程) 中 mask 的指导
- 被编码后的潜在图像(可能带有 mask 信息),以及由 denoising_strength 控制的“涂抹泥巴”操作(加噪),都会作为 KSampler 的输入。
- KSampler 内部的 UNet 模型在去噪时,会接收这个潜空间 mask 作为指导信息。
- UNet 会根据这个 mask:
- 集中在遮罩区域去噪和生成内容。
- 同时,确保在遮罩之外的区域,模型尽量保持原始图像的内容不变,或者只进行平滑的融合。
- mask 在这里充当了“注意力权重”或“区域限制”的作用,告诉 UNet 在哪里可以自由创造,在哪里必须忠于原图。
3.3.4 为什么这样做?
- 计算效率: 在潜在空间中操作比在像素空间中更高效。将 mask 也编码到潜在空间,可以确保所有去噪操作都在同一个低维空间中进行,避免不必要的像素级操作。
- 语义理解: 潜在空间捕获的是图像的语义和结构信息。将 mask 融入到潜在空间,可以让模型更好地理解在什么“概念区域”进行修改,而不是仅仅在像素坐标上操作。
- 平滑融合: 通过在潜在空间中对 mask 区域进行内容生成和与非 mask 区域进行融合,模型能够学习到如何在语义层面实现无缝连接,而不是简单的像素级拼接。
四、理解LoRA
4.1 LoRA 小白理解
4.1.1 LoRA对CLIP模型产生影响
在之前提到,赛博雕塑世界中,需要对咱们的需求(prompt)转换成雕塑家能理解的设计需求说明书(embedding),而这个转换器的规则便记录在CLIP模型中。
lora的其中一个作用便是修改转换器规则(CLIP),大致的作用就是对指定的概念进行约束补充说明,倘若设计需求说明书(embedding)包含了指定的概念,这些概念就会有一个更为详细的扩充说明。
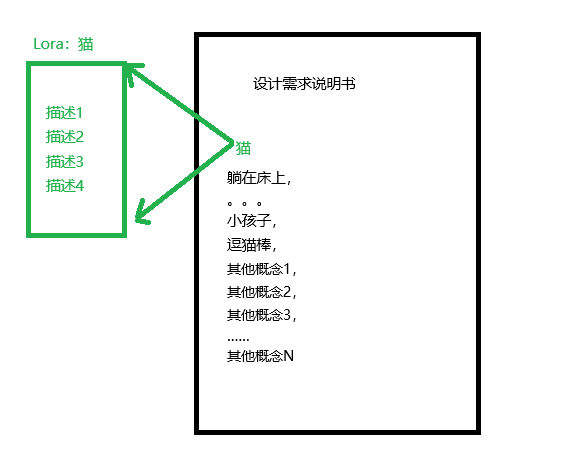
反向理解,如果设计需求说明书中没有lora指定的概念,即时使用了lora,也不会产生啥影响。有趣的是,设计需求说明书中有一些公有概念不会明确表示出来,(如:背景,风格等),lora训练时如果指定了这些概念,就会产生影响。
4.1.2 LoRA对Unet模型(雕塑家)产生影响
前面提到过,unet模型可以理解为一位雕塑家,在创作之前,被要求学习雕刻技艺(对指定的概念应该以什么样的风格/元素进行雕刻创作)。
在这里影响的是雕塑家”真正动手雕刻”的方式
4.2 基本工作流
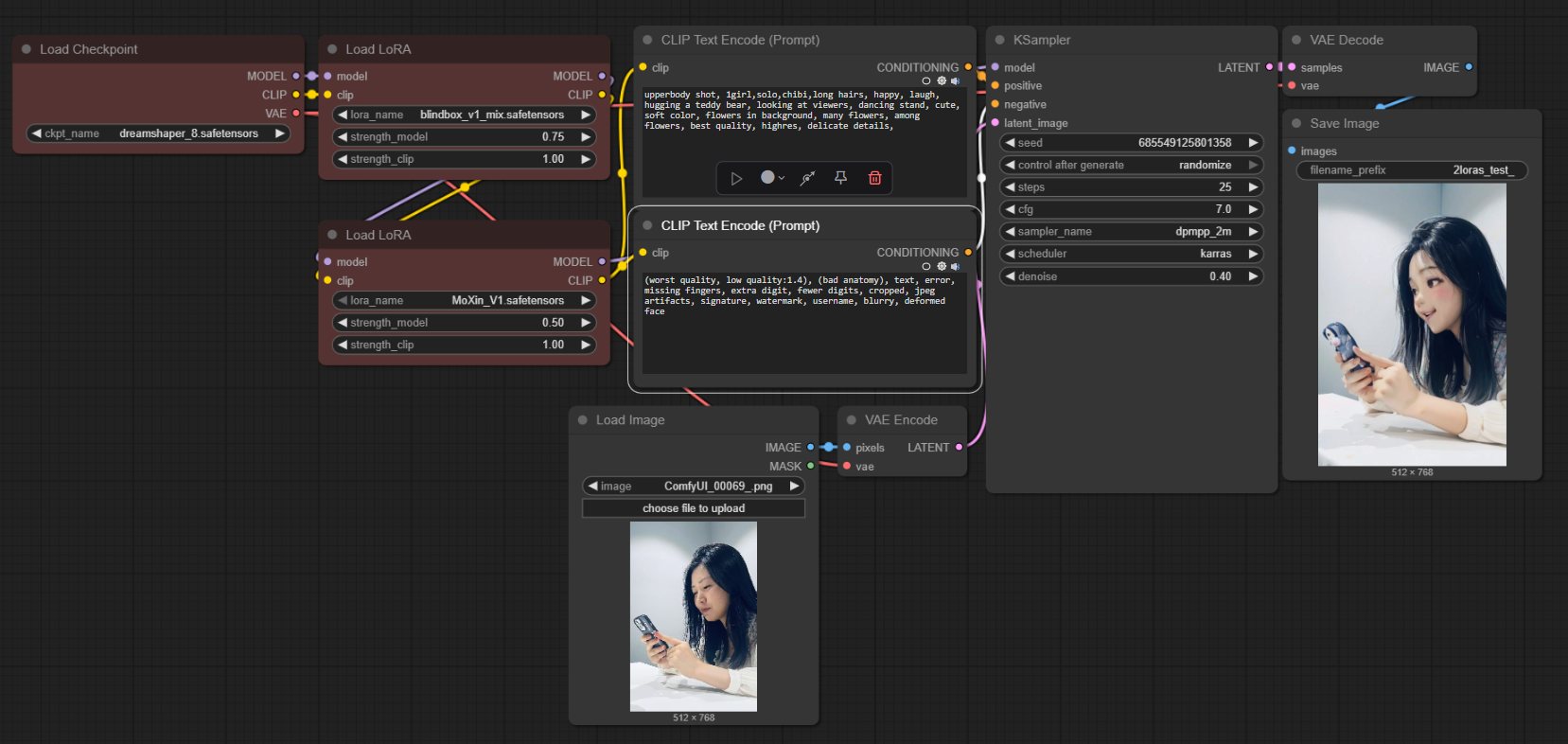
可以看到lora的使用方式是在CLIP text encoder之前
Load LoRA会接收输入:CLIP和model
- CLIP,则是提示词(prompt)转换生成需求设计说明书(embedding)的规则,LoRA会对其进行修改。
- model(unet模型),雕塑家,LoRA要求雕塑家针对指定的概念进行雕塑记忆学习。
输出则是进行修改过的CLIP和model,CLIP是转换器所需,而model则是各种采样器节点(如:ksampler)所需。
五、理解Textual Inversion (Embedding)
5.1 小白理解
如果说Lora的作用是在需求说明书中的某个现有概念进行扩充约束说明,那么Textual Inversion (Embedding)更像是新增一个概念,并且自带扩充约束说明。
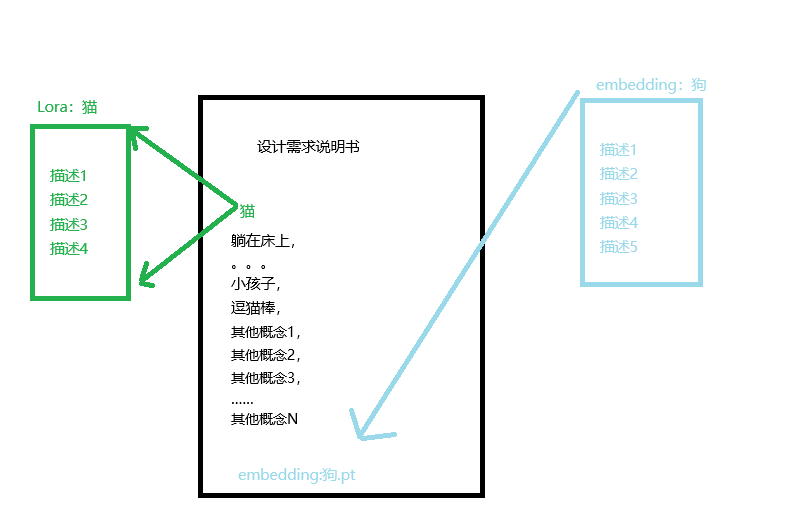
5.2 基本工作流
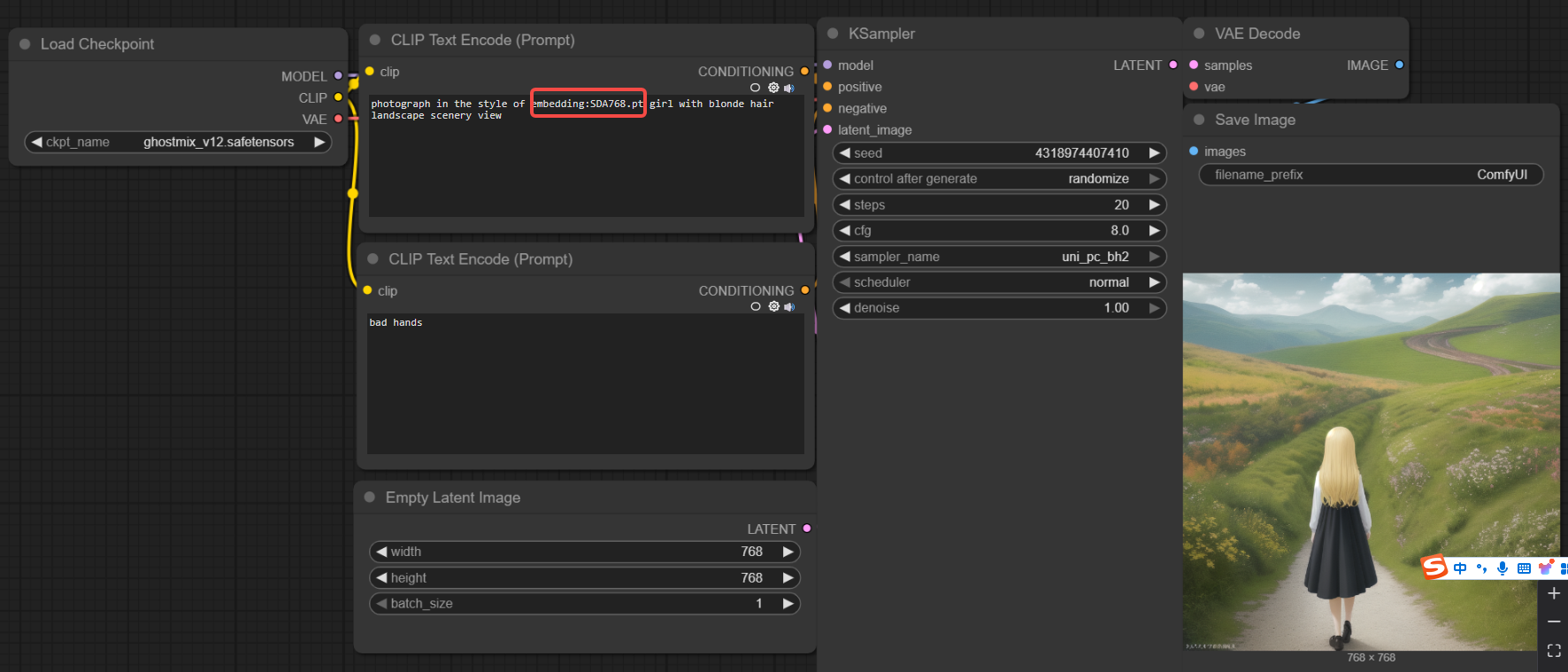
可以看到,Textual Inversion的使用方式是在CLIP text Encoder中直接通过形如embedding:xxxx.pt的形式进行使用,而xxxx.pt文件一般存在于 comfyUI根目录/models/embeddings 目录中