引言
Stable Difussion的作用主要是生图,而图片之所以能产生价值,一定是符合应用落地的某些需求,这就要求咱们从”随机生成”逐步迈向”精准控制”。
目前在comfyUI中,大致有这么几个主要方式可以进行控图。
- 模型本身,提示词,LoRA,TI
- IPAdapter
- ControlNet & InstantID
本文主要就图像条件可控-IPAdapter进行总结。
一、初步认识IPAdapter
维度 | 描述 |
|---|---|
定位 | 图像风格/内容转化师。它通过图像来影响 AI 绘画的风格、身份或视觉元素。 理解全名,辅助理解其作用Image Prompt Adapter。 |
输入/输出 | 输入
输出
|
作用点 | 主要作用于 UNet 模型的注意力层,让 UNet 在去噪过程中能“看到”并融合图像的视觉特征。 |
与pormpt关系 | 与文本 Prompt 并行工作,Prompt 定义“什么”,IP-Adapter 定义“像什么” |
二、IPAdapter基本工作流
2.1 工作流图示
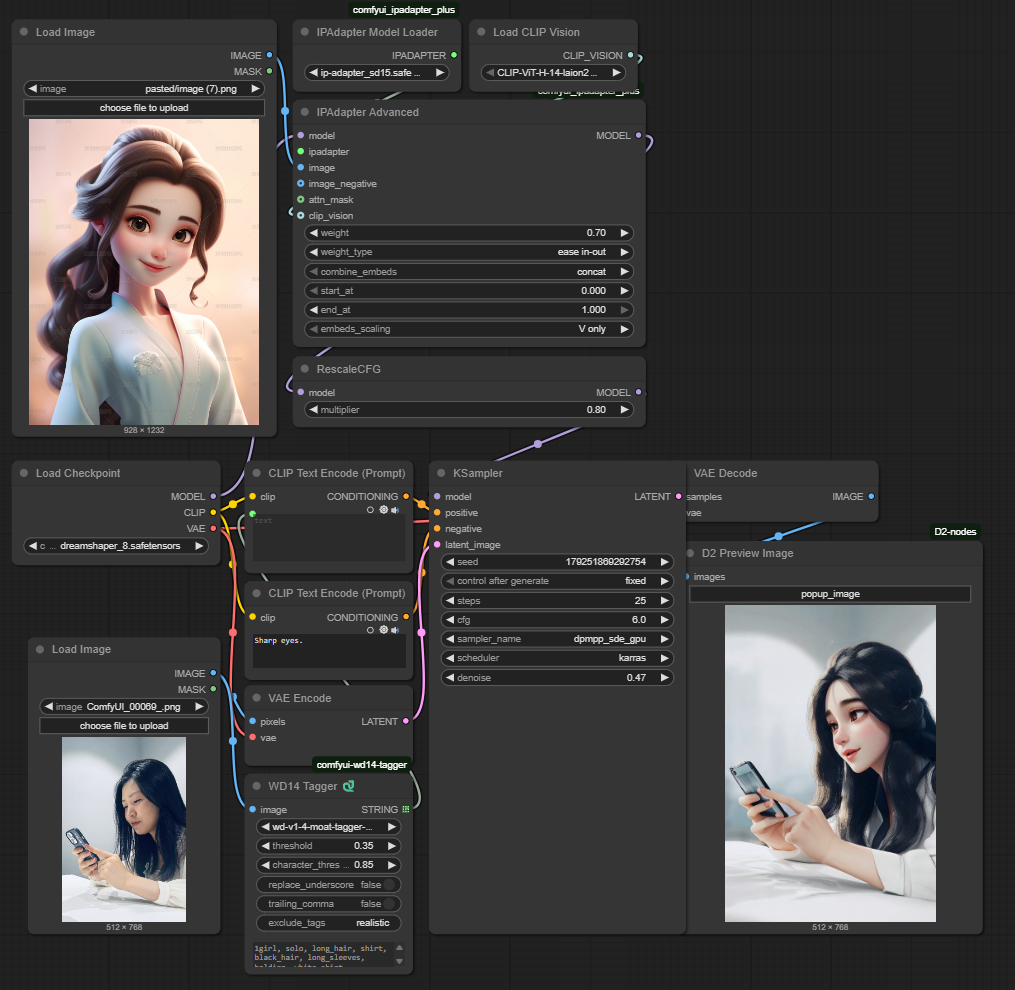
2.2 基本节点介绍及参数理解
节点名称 | 描述 |
|---|---|
IPAapter Advanced | 好比一个训练场 核心输入
额外参数输入
|
Load CLIP VISION | 加载CLIP Vision Encoder,需要选择 CLIP Vsion Encoder,作为IPAapter Advanced的核心输入之一。
原则上G>H>L,越大能识别的信息更多。 |
Load Image | 参考风格图片,通过CLIP Vision Encoder将其提取成视觉信息,作为IPAapter Advanced的核心输入之一。 |
IPAdapter Model Loader | 定向训练官,用于将视觉信息定向筛选并让雕塑家(模型)学习,作为IPAapter Advanced的核心输入之一。 值得一提的是,既然是从转换后的视觉信息中筛选,很大可能IPAdapter Model和CLIP Vision Encoder有匹配关系,事实也确实如此。 命名形如*-h的模型通常对应ViT/H 命名形如*-g的模型通常对应ViT/G 其他依次类推,无特殊信息的话,如果报错,可以先尝试用ViT/H的视觉编码器。 |
Rescale_CFG | 控制最终所有条件引导强度的核心参数。它通过校准 Prompt 和 Adapter 共同产生的“合力引导方向”的强度,来平滑高 CFG Scale 和强 Adapter 可能带来的过度引导问题,减少伪影,使图像更自然、美观。 同时,在某种意义上也能达到这种效果:
|
三、IPAdapter-FaceID
在生成图像时,除了参考风格外,常常还有这么一个场景,即:生成的作品中,如何精确地保持人物的脸部身份和特征
3.1 基本工作流
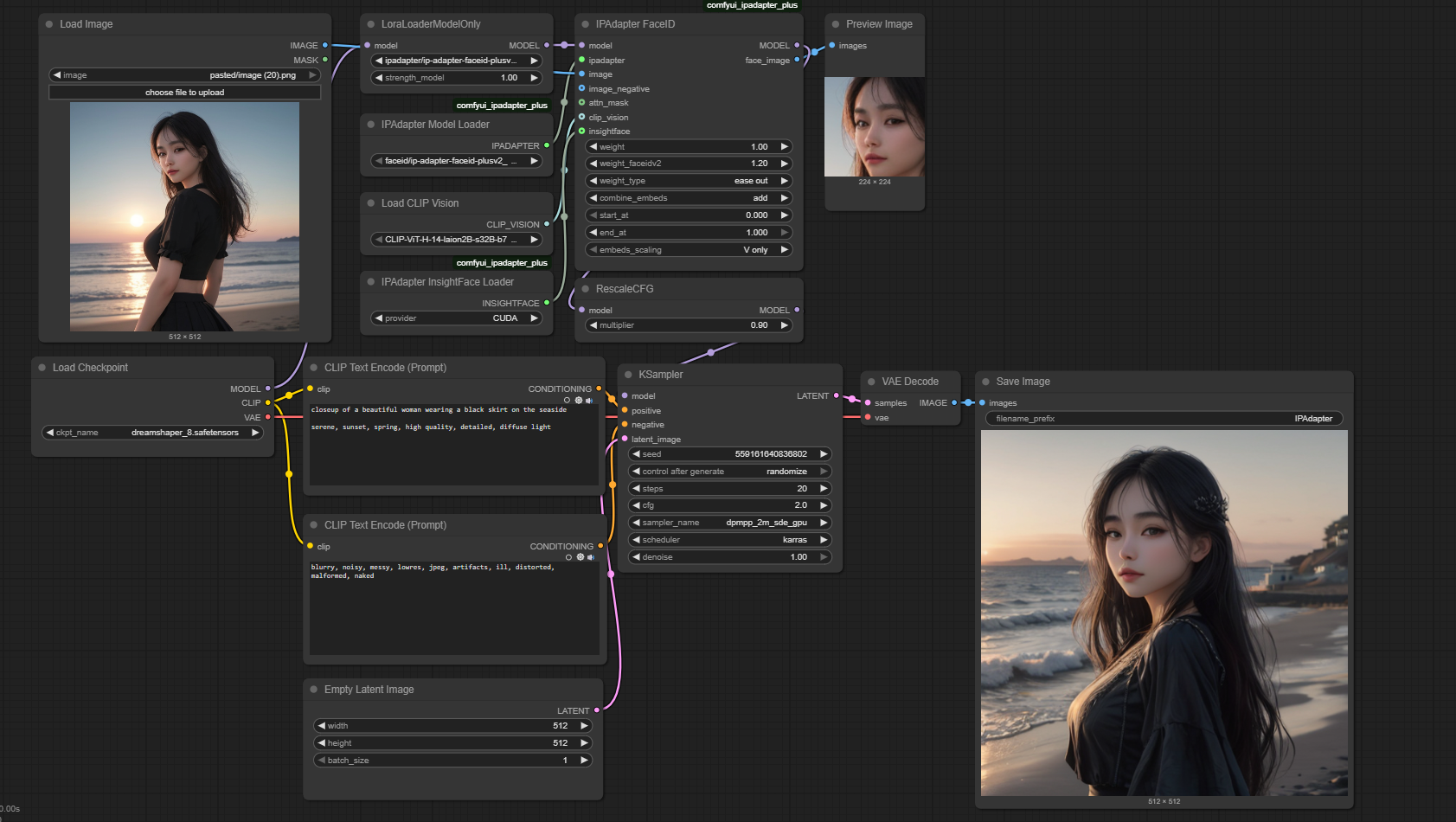
3.2 基本节点和参数理解
节点 | 描述 |
|---|---|
IPAdapter FaceID | 与IPAdapter Advanced类似,输入有:
|
IPAdapter Model Loader | 略,同基本工作流 |
Load Image | 略,同基本工作流 |
Load CLIP Vsion | 略,同基本工作流 |
LoraLoaderModelOnly | 《ComfyUI,SD小白入门篇》中提到,LoRA即会影响Unet Model,又会影响CLIP,但FaceID这里只需要影响UnetModel,如果还是通过原有的Load LoRA节点进行加载,工作流的线条连结会变得更复杂,因此,这里推荐使用LoraLoaderModelOnly节点。 |