引言
为避免陷入学习陷阱,以阶段性目标为导引,约束学习路径。
本期学习目标为实现一致性角色,最终表现为训练一个Flux LoRa模型,整体思路为:
- 人物角色初始化:得到一张满意的T-POSE正面全身照和高清的头部图像。
- 角色多视角实现:基于初始化角色,得到不同视角的的图片。
- 丰富角色表情:给所有图片增加表情。
- 丰富背景:给增加表情后的图片增加背景。(至此,得到训练模型的图片素材)
- 素材处理:给素材批量修改大小及打标。
- 模型训练。
一、人物角色初始化
此步骤较为简单,目标有两个。
- 获得一张T-POSE正面全身照。
- 得到头部的高清放大图,作为之后脸部特征的依据。
1.1 T-Pose角色图生成
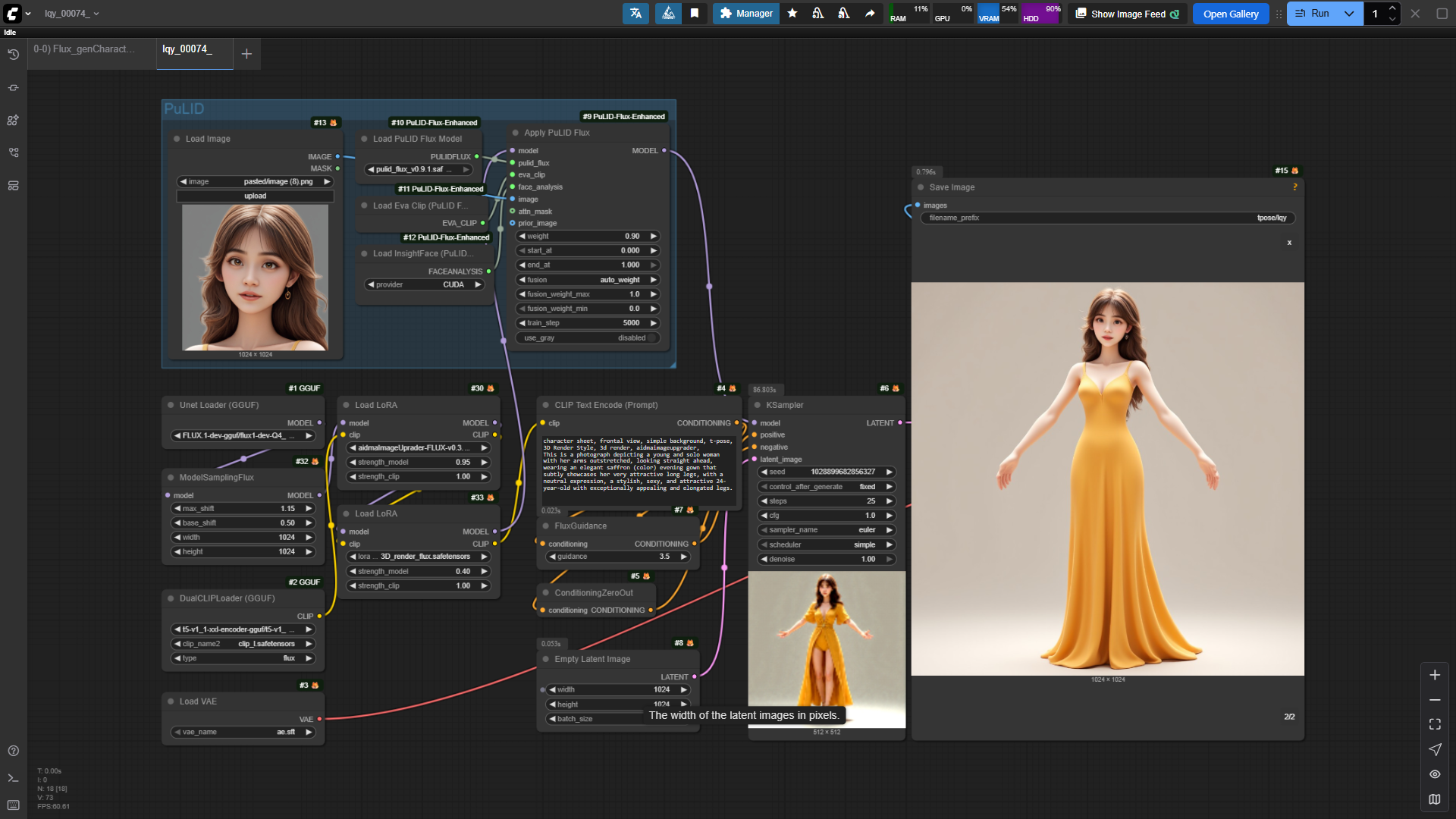
此处采用的是FLUX模型。
一般来说,获取一个角色要么随机,要么是想这个角色带有某个目标人物的脸部特征。在Flux中,可加入一个PuLID模块,用于提取目标人物的脸部特征。
工作流图示如下:
1.2 头部高清放大
基本思路:
- 提取T-Pose角色的头部区域
- SD放大+FaceDetail,SD放大过程中为防止和原图相差过大,通过图片反推提示词+ControlNet_Tile保留原图特征。
- 为保留原角色图片色彩风格,增加一个色彩匹配节点。
工作流图示如下:

二、角色多视角图
此步骤主要目的是基于第一步得到的正面T-Pose图片得到多视角图,整体思路为:
- 获取多视角参考图,为后续的图片生成提供Controlnet引导(Pose,depth,cany)。(如果已经有了多视角CN控制图,可以省略此步)
- 基于T-Pose图,在多视角参考图提供的CN控制下,生成多视角图片。
- 由于参考生图通常会使得面部特征相差较大,还需进行脸部处理,用换脸思路即可。
2.1 获取多视角参考图
可以在网上搜寻多视角的参考图,关键词如:pose sheet,但通常很难得到能直接用的参考图。

有些UP/博主也会直接分享通用的CN控制图,如下图,但抽卡表现上稳定性不高。
在多次实践后,为生成较为稳定的结果,本次采用的思路是:
- 利用MV-Adapter,基于T-Pose图先生成六视角图,虽然细节特征会相差较大,但整体身型/色彩的一致性有较好表现,之后提取的CN控制图会较为契合目标。
工作流图示如下:

2.2 生成多视角角色图片
前置准备:
T-Pose图提供整体身型、服饰、发型等元素信息,多视角参考图提供CN-控制信息(本次使用是Pose图)。
整体思路:
- 利用Fill+Redux的组合,可以生成和T-Pose相似的图片(整体身型,内容,色彩等),但缺点是姿势不能控制。(PS: Comfyui自带的Redux相当强大,极难更改姿势信息,建议使用Redux Adv)
- 在Fill+Redux的基础上,增加Controlnet模块,控制姿势。
工作流核心图示如下:
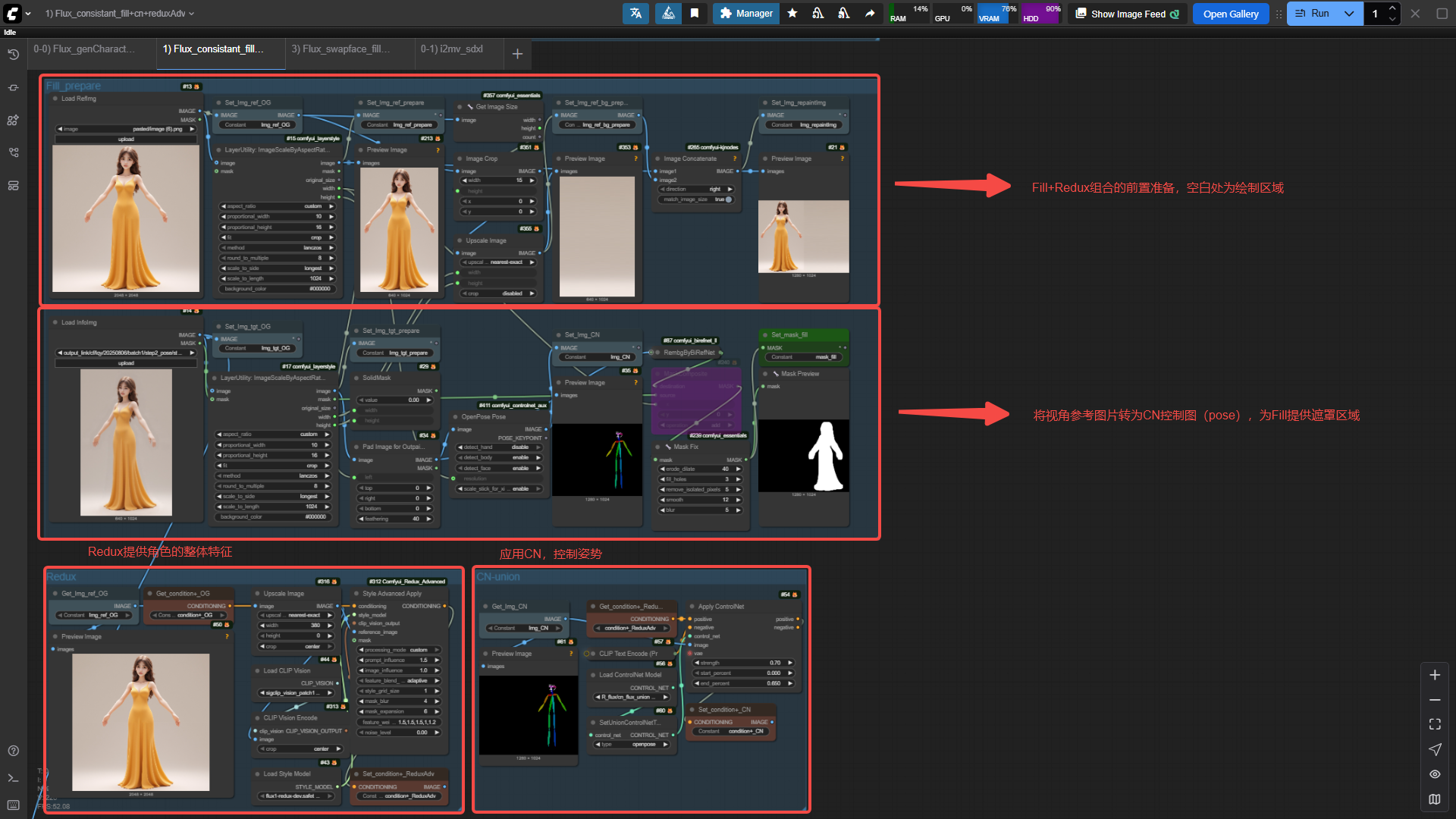
Fill+Redux组合工作流采用后得到想要的多视角图片

2.3 换脸
2.2 生成的多视角图虽然整体内容非常相似,但在脸部特征上会有较大区别,所以会在此基础上,利用换脸工作流进行脸部特征处理,此时1.2步骤中得到的头部图就起到了比较好的作用。
换脸工作流较多,SD1,5/XL或Flux都有较为成熟的处理方法,本次采用的是Flux,整体思路为:
- 将目标图片(需要换脸的图片)的头部区域截取下来。
- 将其Resize到100W像素左右(+-30%),Flux在此大小上生成效果较好。
- 通过Fill重绘,对截取后图片的脸部区域进行重绘,此处同时采用了PuLID+Redux+Ace(Potrait)进行脸部特征提取。
- 将重绘后的图片还原到目标图片上。
工作流核心图示如下:
重绘前的准备

Fill+Redux+Ace(Portrait)+PuLID应用:
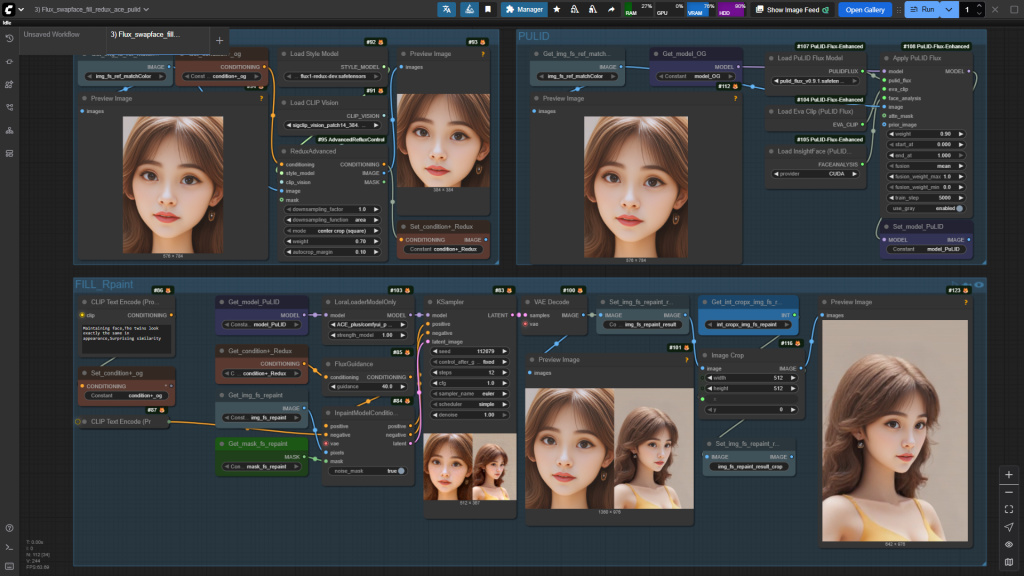
将重绘后的脸部区域还原到目标图片中

三、丰富角色表情
此步骤的目标为生成的多视角图进行表情处理,整体思路为:
- 图片剪裁,只保留肩部以上区域。这样大多的素材会集中在头部。
- 表情移植
3.1 图片剪裁
略,随便搭个工作流即能批量处理即可
3.2 表情移植
表情移植的一个准备工作是找到表情参考图片,方法有很多,这里列举一些:
- 可以自己生成一些表情图,但是通过基本模型生成的人物表情不够丰富,可以寻找一些表情LoRa.
- 寻找一些现成的表情参考图,如搜索关键词:Expression Sheet.
有了表情参考图后,就可以利用livePortrait进行表情移植,值得一提的是,LP在不同风格(写实、3D、2D)的表情移植上不如人意,特别是眼睛的表达上,在此,经过大量实践,得到以下工作流。
工作流图示如下:

四、丰富背景
丰富背景的方式有很多,Flux也可以利用Fill+Redux重绘的方式进行背景更换,本次采用的是IC-Light,截止写作为止,IC-Light本地部署只支持了SD15,效果上,会兼顾背景和光影效果。
工作流图示如下:
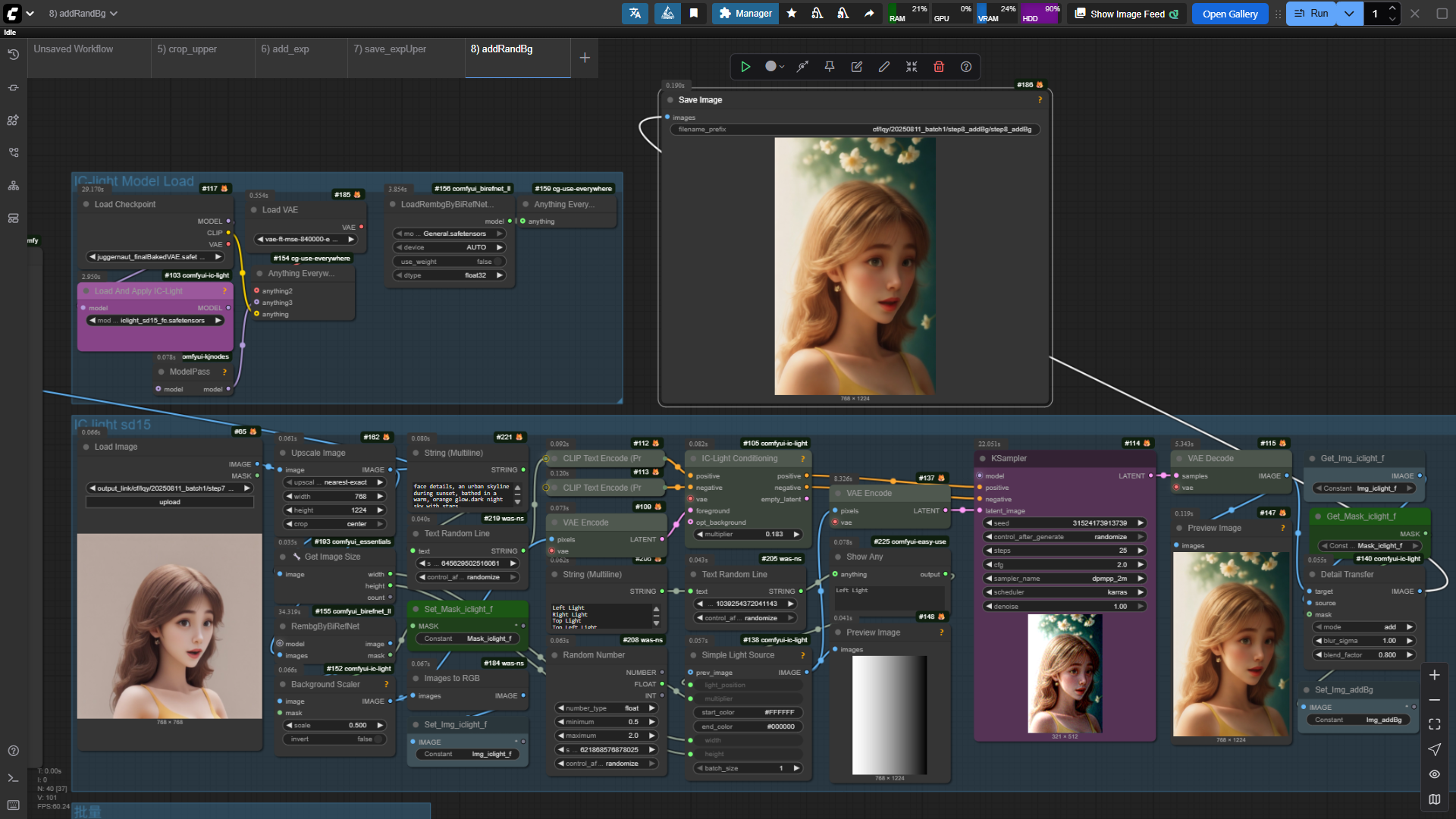
至此训练素材就生成完毕(生成过程中,其实也可以用InstantID保持脸部特征)
五、素材处理
5.1 图片大小的预处理
由于本次生成图片都是768*768,比较符合训练需要,所以实践中赞未涉及。
略
5.2 图片批量打标
很多模型训练工具都提供了打标功能,如Fluxgym、秋叶模型训练器等,但是都有其缺点,目前采用的是joy caption,注意:触发提示词尽量要用一个不常见的词,实践中用的Utwin其实并不可取。
工作流图示如下:
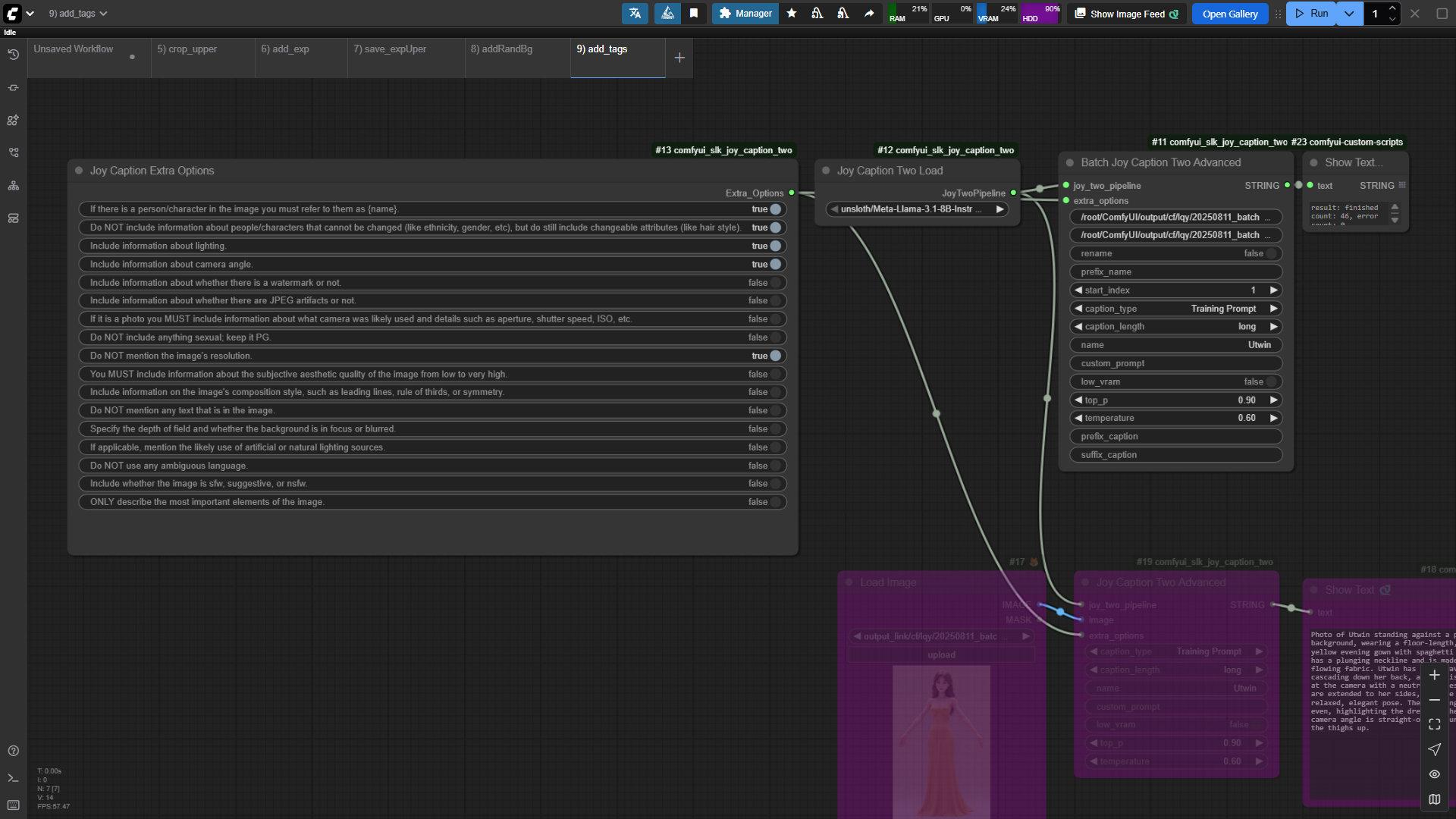
六、模型训练
模型训练,可以随便选一个训练器,本次实践中采用的是秋叶模型训练器。
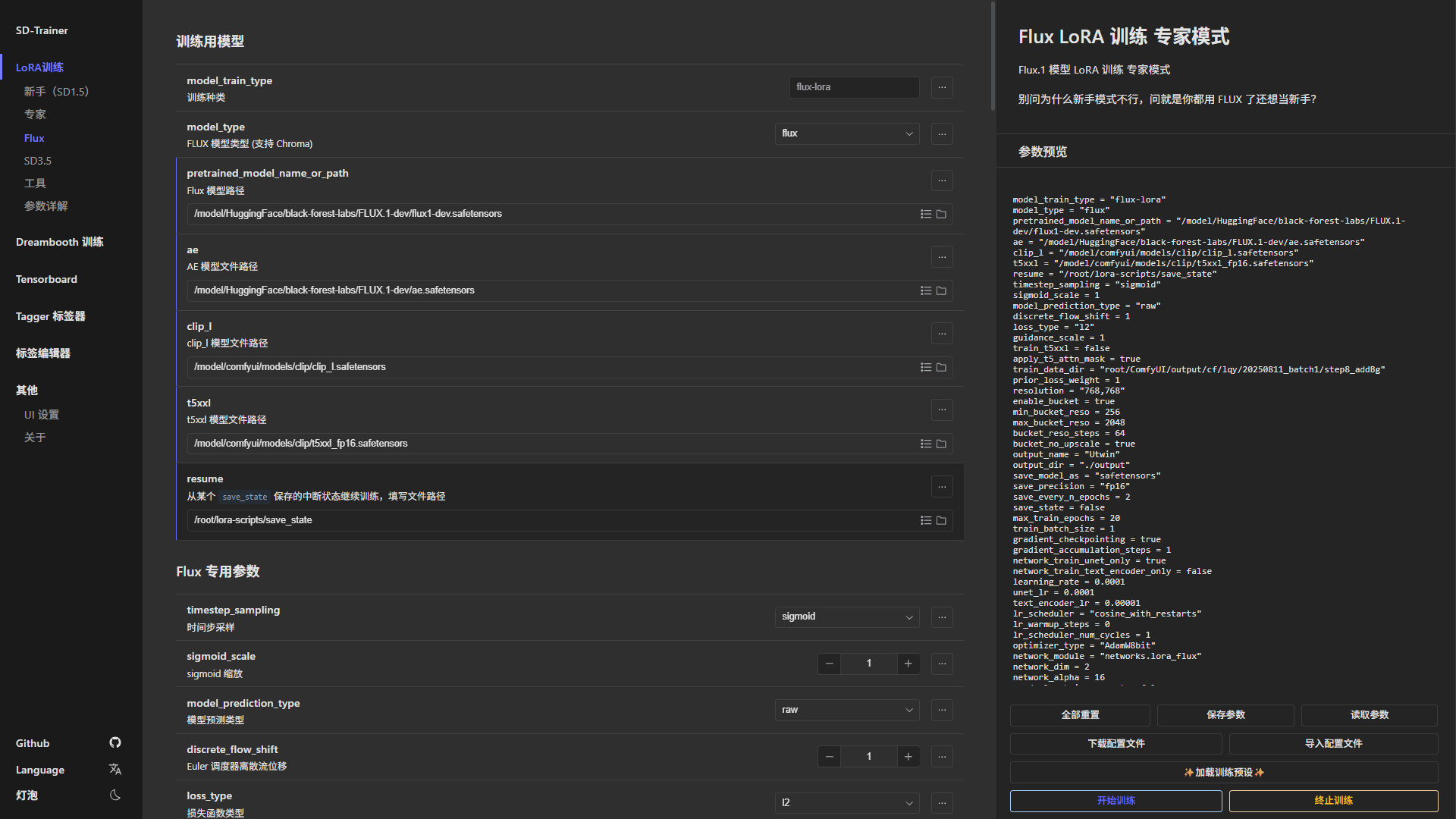
主要参数:
- 每张图片训练次数/epoch,没地方设置,但是实际是5次/img,当你开始训练时,会将图片路径下的所有图片打包到一个文件夹,以times_randomtext的形式进行命名,times即表示每张图片训练多少次。
- epoch总数,实践设置为10
- 每2epoch保存一次模型
- network_dims为32
- 学习率:1e-4
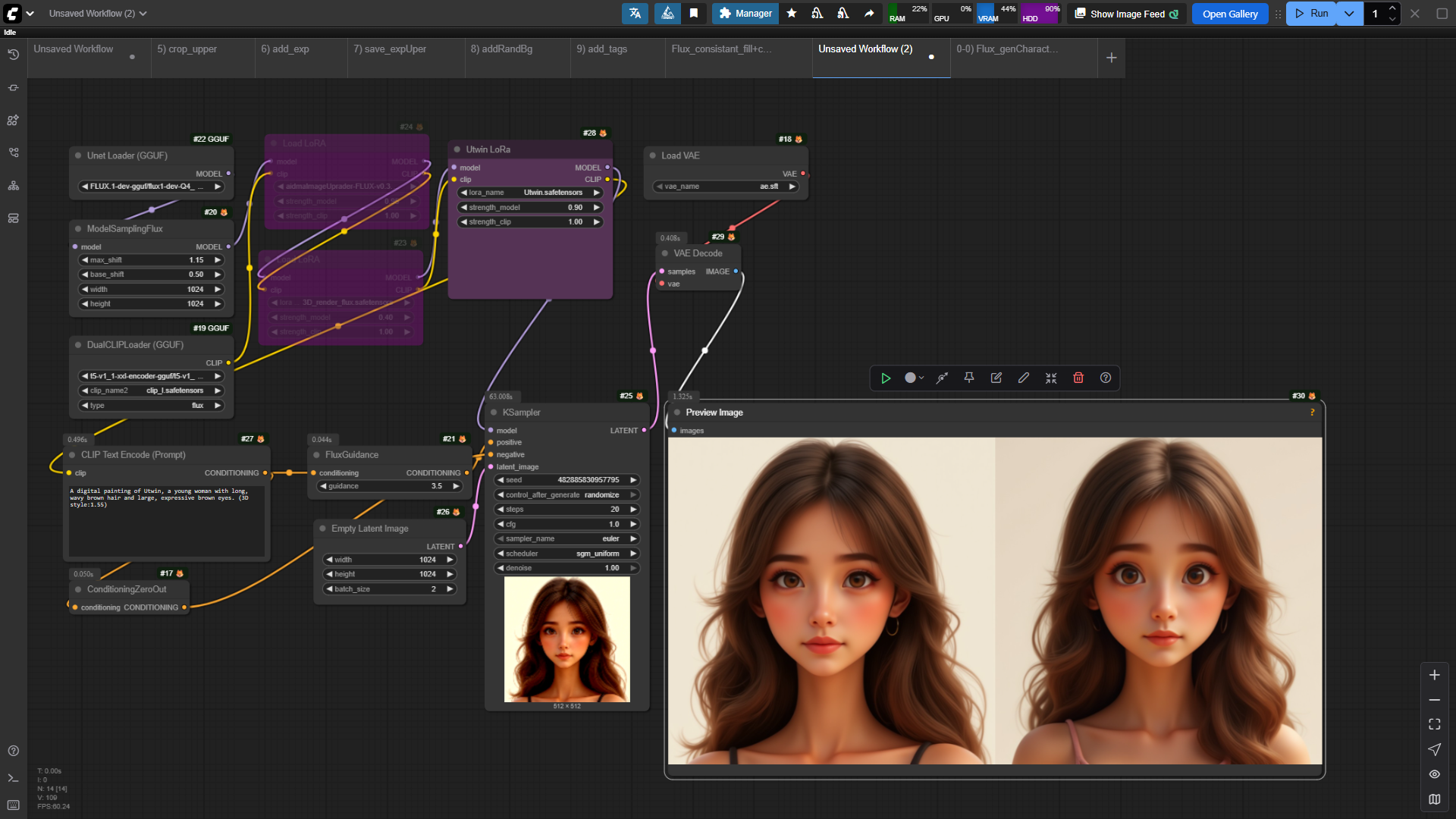
这是第一次进行模型训练,有很多影响因素值得研究,仅这次而言。
- 模型明显将发型及晚礼服肩带特征学习进去,这不在目标范围,明显和素材及打标方式强相关。
- 脸部特征其实并没有达到我想要的程度,不过在3D风格上有意想不到的效果
实际生图效果如下:
至此,人物角色一致性的实战就到此告一段落,每个步骤都有多种方式实现,之后会尝试以视频的方式进行分享讲解,敬请期待。