引言
本篇文章的阅读前置条件(必须):
介绍内容包含:
- 核心概念的理解
- 基本工作流及主要控制模块总结
在《ComfyUI,SD基础总结篇》中,我们已经了解了 Stable Diffusion 1.5 和 SDXL。它们就像拥有精湛技艺的“雕塑家”,从“混沌石料”中一步步雕刻出令人惊叹的作品,代表着当前主流的 AI 图像生成技术。
现在,是时候揭开 AI 绘画领域另一条前沿技术路径的面纱了——介绍 Flux。Flux 不再是 SDXL 的简单升级,它代表了图像生成方式上的一种架构创新,为 AI 绘画带来了新的可能性。它并非要取代 SDXL,而是提供了一个不同的、有潜力的技术方向。
一、Flux核心理解
虽然在底层技术原理上,会有较大的区别。但在应用层的理解上,我们仍然可以使用SD15/XL的理解《ComfyUI,SD基础总结篇》,一句话:
独具特色的雕塑家拿着原始石料在设计需求说明书的指引下按某种雕塑策略进行雕塑创作,同样的,也有以下核心概念。
- 雕塑家:Diffusion Model,每个雕塑家都有自己的特色,如:Flux1-dev,Flux1-fill-dev,Flux1-cany/depth-dev,Flux1-kontext等。
- 原始石料:latent image,潜空间图像,SD1.5&SDXL&FLUX都是在潜空间进行图像生成的,至于为什么需要在潜空间中进行,最大原因是能极大的压缩空间,使得寻常硬件得以计算。总之,可以将其理解为创作所需的原始石料,以下如何获取原始石料的方式:
- 直接提供latent image,设定长宽。
- 将原始空间图像(寻常人眼感知的图片)通过VAE Encode的方式转换成潜空间图像。
- 作品去色/上色器:VAE Encode/Decode,将原始空间图像(人眼寻常感知的图片)转变成潜空间图像,这个过程也称为编码Encode,好比对雕塑成品进行去色,从而得到石料本体;同时也支持从潜空间图像转换成原始空间图像,这个过程称为Decode,好比对雕塑完毕的石料本体进行上色。这个去色和上色规则记录在VAE model中,即需要加载这个模型。
- 设计需求说明书:Text Embedding(pos + neg),用于指导雕塑家进行雕刻,雕塑家每次雕刻都需参照设计需求说明书。如何获得需求设计说明书:
- 通过一个转换器Text Embedding Encode将自然语言(人类语言,通常是英文)转换成雕塑家能理解的设计需求说明书,转换规则被记录在CLIP model中,即需要加载这个模型。
- 雕塑策略:调度器(scheduler)、去噪步数(steps),采样器(sampler)。其好比雕刻策略,先制定整个雕刻计划(“路线图”),决定了在整个生成过程需要去除的石料应该如何逐渐减少;再定义执行步骤数量,越多,耗费时间越长,就越细致;最后,基于路线图,在每一步中具体执行雕刻动作,计算并将多余的石料进行雕刻去除。
二、核心组件/概念理解
主要介绍与SD15/XL有区别的一些组件和概念
- DualCLIPLoader:和在SD15及XL中一样,Flux依然需要一个CLIP模型将自然语言转换成设计需求说明书,只是这里需要指定两个模型:CLIP_I和CLIP_T5。其设计思路与SDXL基本一致。
- LoadVae:与SD15和XL不一样的是,Flux在使用上会单独指定配套的VAE模型,一般名称叫ae.sft或者ae.safetensors.
- FluxGuidance:此处与SD15和XL有较大区别,对标其CFG。
- Flux将引导条件融合到一起,不再区分positive和negative。(若使用ksampler,negative可接空条件)
- 在flux的实际使用中,不再使用cfg参数,取代而代之的是guidance参数,表示条件引导的程度。(若依然使用ksampler,将其设置为1,否则会产生糊图。)
- guidance的参数值,在Flux1-dev中,一般设置为3.5,在Fill+redux组合使用中,一般在[30-50]中选择。
- Redux:Flux提供的配套风格模型,就实际使用效果来说,其实就是通过Clip vision encode提取参考图的细节信息,再通过apply style model(redux模型作为规则转换器)并将其补充到设计需求说明书中,值得注意的是,redux的引导强度相当强烈,若使用原生自带的节点,基本上很难和CN及其他控制模块共同作用与图像生成,建议使用redux adv节点(实测有效)。
三、Flux工作流总结
在实践探索过程中,FLUX在思路上和SD15/XL并没有什么大的差别。先学习了基本文生图/图生图/重绘之后,再加入一些其他控制模块,主要包括:
- LoRa:有一些比较有意思的LoRa,包括消除LoRa,图像编辑LoRa
- IP-Adapter:对雕塑家进行增强训练(风格内容参考)
- PuLID:对嗲苏佳进行增加训练(脸部参考)
- Controlnet:对需求设计说明书进行补充说明
- Redux:对需求设计说明书进行补充说明
这样就能得到FlUX工作流的各种变体。
本部分主要介绍内容:
- FLUX.1-DEV基本工作流
- FLUX.1-FILL-DEV基本工作流
- Redux模块&其余控制模块,和SD15/XL其实并为太大区别
FLUX.1-cany/depth模型并无太多应用场景,此处主要对FLUX特有的模块进行进行介绍,另外对FLUX.1-DEV和FLUX.1-FILL-DEV模型进行工基本作流总结。
3.2 FLUX.1-DEV 工作流
3.2.1 基本文生图
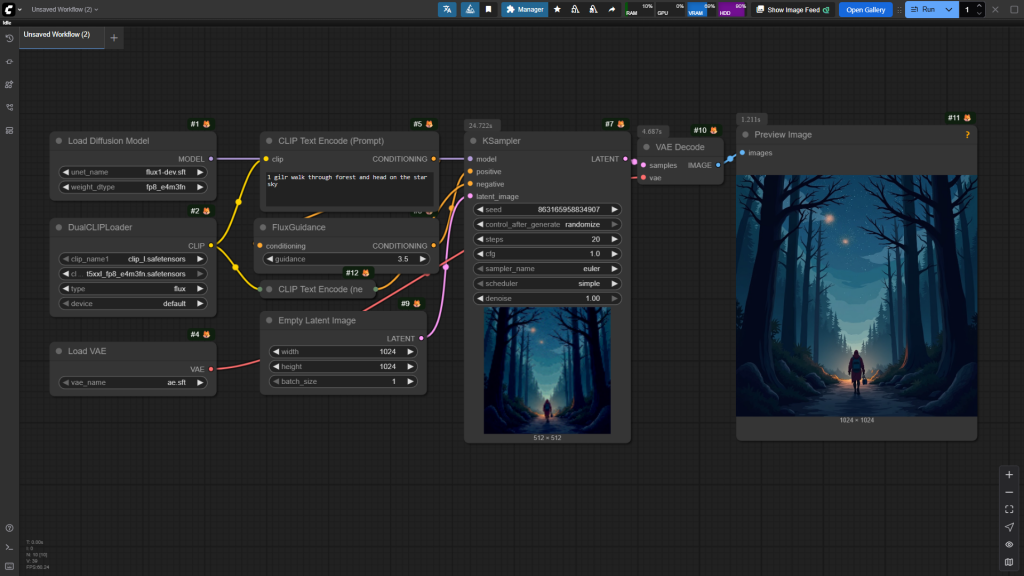
和SD15/XL差别不大,主要区别在于:
- model/clip/vae的加载方式不一样:
- model的加载节点是Load Diffusion Model
- clip是dualcliploader,需要指定一个Clip_I和T5模型
- vae也要单独指定与Flux配套的模型,ae.sft
- ksampler使用变化
- 中的cfg参数固定为1(该参数已经没啥用了),设计需求说明书的遵循程度变为了另一个flux参数:guidance,越高,约束能力越强,反之越能发挥自由度。
- 由于Flux不再区分正负prompt,使用ksampler时,neg-prompt为空即可。
3.2.2 基本图生图
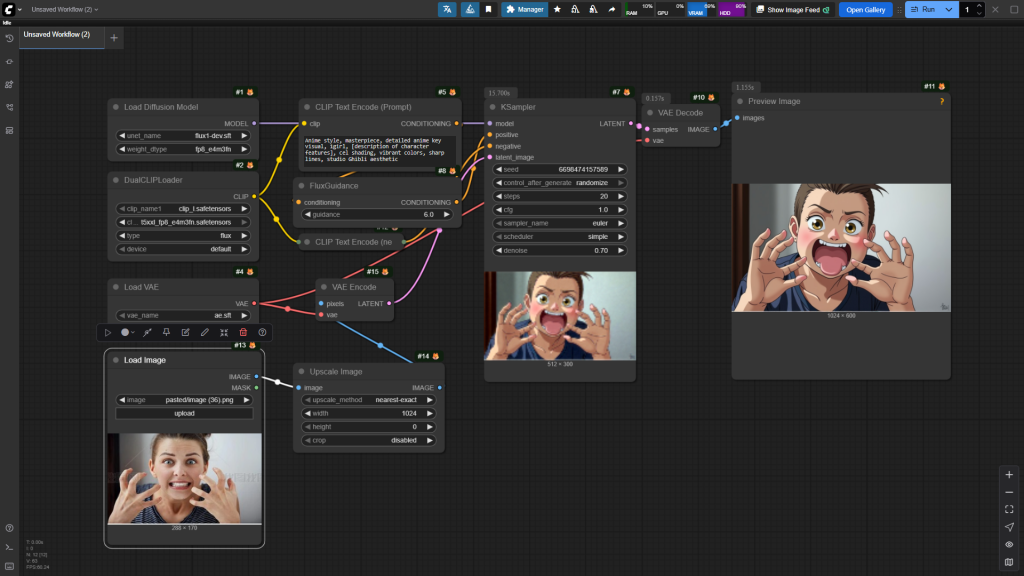
没什么好说的,一般来说很少用到直接图生图的情况,目前就两种:
- 放大图生图重绘增加细节
- 粗略的风格转绘
3.2 FLUX.1-FILL-DEV工作流
3.2.1 局部重绘(inpaint)
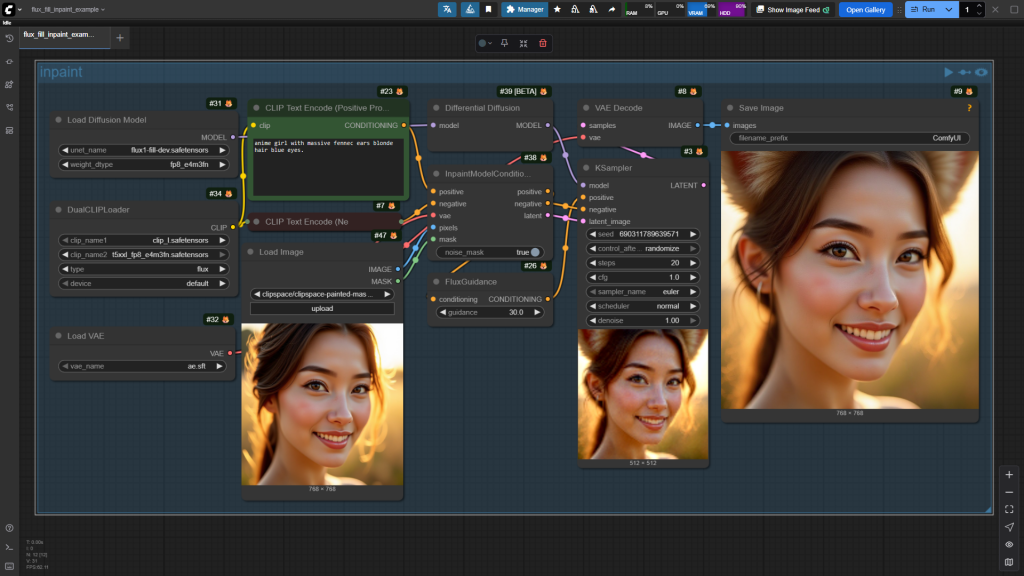
大方向和SD15/XL类型,在使用上有以下差异:
- 重绘时,是用FILL模型
- 基本工作流中,FluxXGuidance参数一般设置为30,也可以尝试其他的。
- FILL模型的所有工作流中,都建议加入一个节点Differential Diffusion,它的核心作用正是参照一个已有的图像,从而让新生成的内容在风格、色彩或氛围上与之保持协调一致。
3.2.2 扩展绘制(outpaint)
所谓的扩展绘制其实和重绘区别不大,只是不图片原有区域进行绘制,增加新的区域进行内容补充。
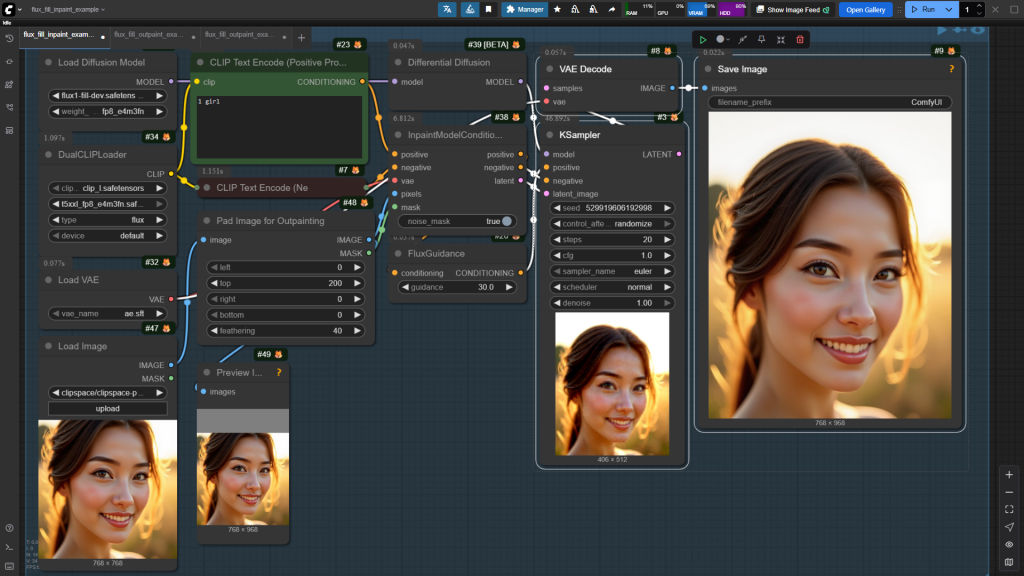
3.3 FLUX其他控制模块
3.3.1 一些好玩的LoRa
- 消除LoRa,结合FILL模型,可以很好的消除不需要的元素,也能起到修复效果。
- 加速LoRa,能让出图步数控制在8步甚至4步内。
- 编辑LoRa,结合FILL模型,能实现图像编辑效果。具体在此不再细说
3.3.2 FLUX.1-Redux-DEV 模块
Redux是Flux中特有的一个模块,使用工作流图示如下:
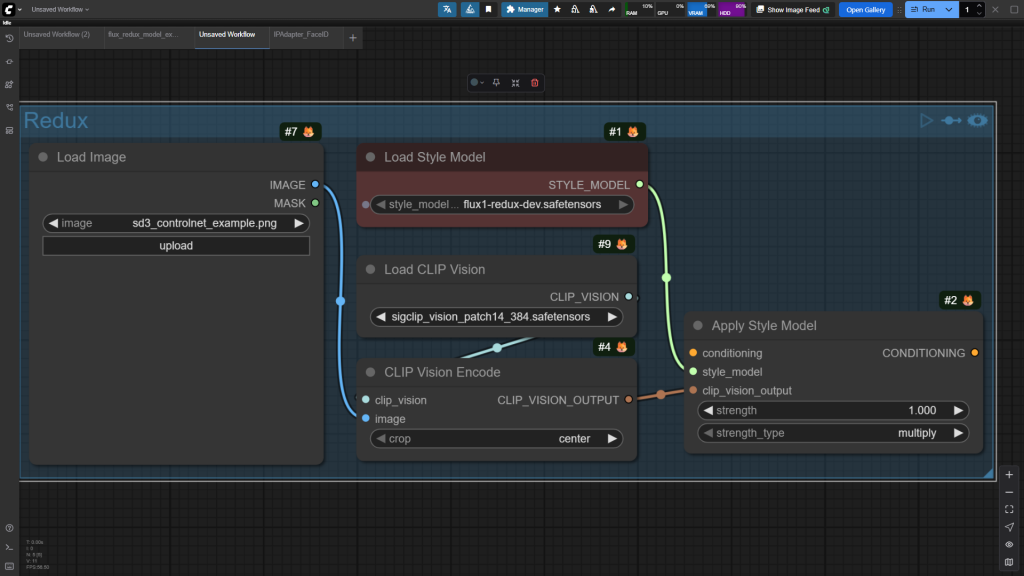
基于输入输出来看这个模块,其实就两个步骤:
- 其实就是将图片信息抽取出来(CLIP Vision Encode),CLIP Vision模型提供抽取规则。
- 再将抽取的信息通过一个转化器(Apply Style Model)增加到需求设计说明书中(Embedding),Redux模型提供转换规则。
就实践而言,Redux对整体的色彩风格、内容、结构都提取得比较到位,但是在一些细节特征上表现不太好(如脸部特征)。
3.3.3 Flux IPAdapter模块
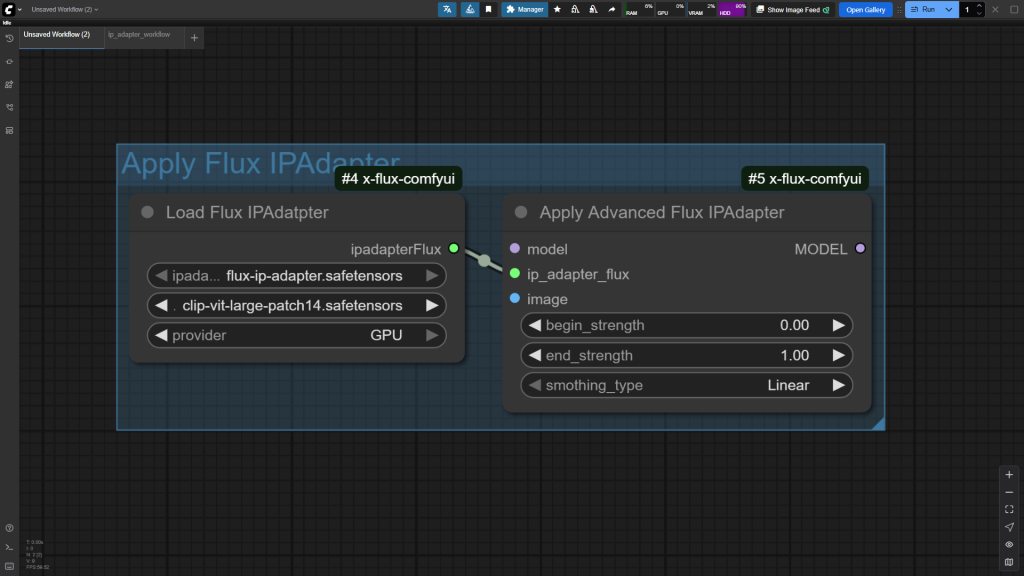
使用上,和SD15/XL区别不大,需使用xlabs团队提供的x-flux-comfyui插件
基于输入输出来看这个模块,
- 其实就是先基于CLIP Vision模型的规则将图片信息抽取出,在通过FLUX Adapter模型对雕塑家(diffusion model)进行训练。
3.3.4 PuLID模块
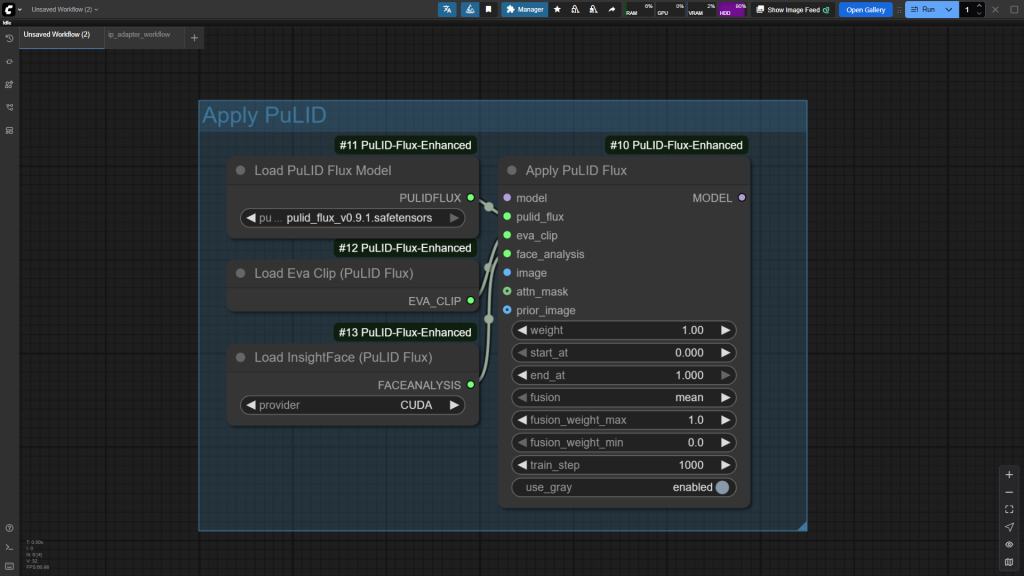
对标FaceID,SDXL中也可使用。
使用FLUX版本需要结合PuLID-Flux-Enhanced插件使用。
用于提取脸部信息,并让雕塑家(diffusion model)增强训练学习.
3.3.5 Controlnet
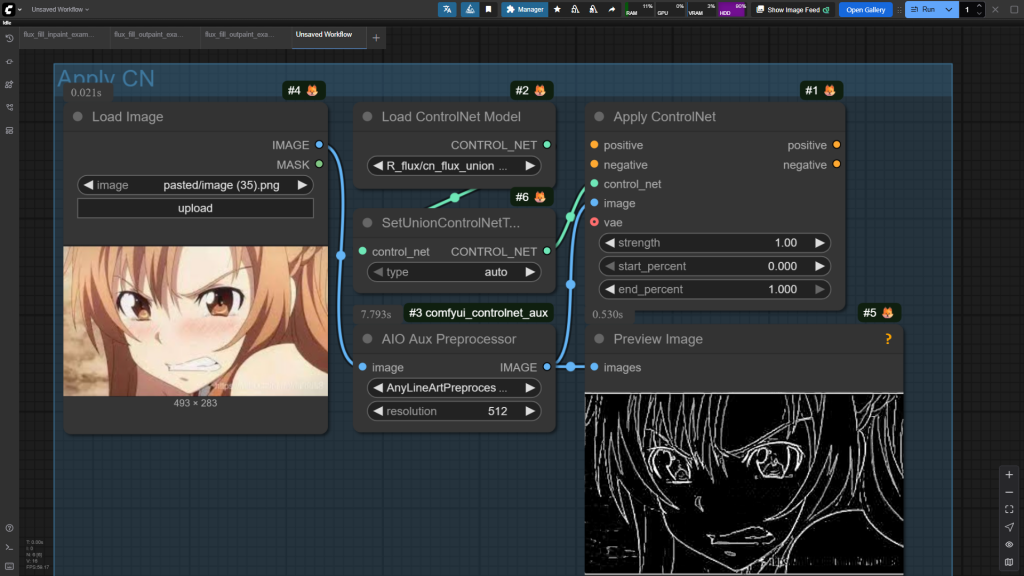
没什么好说的,为设计需求说明书增加额外条件信息。
三、最后
Flux的的变体工作流基本上就是基本工作流+控制模块的灵性组合,后续有机会可能出视频或者直播进行细致讲解,敬请期待。